Kling動画 3.0 能力アップグレード
 |
能力項目 | Kling動画 2.6 | Kling動画 3.0 | |
テキストからの動画生成 | ✅ | ✅ | |
画像からの動画生成 | ✅ | ✅ | |
先頭/末尾フレームからの動画生成 | ✅ | ✅ | |
ネイティブ音声・映像同期 | ✅ | ✅ | |
スマートカット割り | ❌ | ✅ | |
先頭フレーム+エレメント参照 | ❌ | ✅ | |
三人以上の人物の指示 | ❌ | ✅ | |
多言語(中・英・日・韓・西) | ❌ | ✅ | |
方言・アクセント | ❌ | ✅ | |
15秒までの生成 | ❌ | ✅ | |
柔軟な秒数指定(3〜15秒) | ❌ | ✅ | |
Kling動画 3.0 モデルのハイライト
1)スマートカット割り:AI監督が参入、ワンクリックで映画感を実現
単一カットの羅列に別れを告げ、AIがあなたの脚本を理解します。新たなスマートカット割りシステムは、Prompt内のシーン転換を鋭敏に捉え、画角とカメラポジションを自動でコントロール。古典的な対話のショット/リバースショットから、高度な台詞のカット間連携、オフスクリーンボイスまで、様々な高度な映像言語に精密に応答します。面倒なポストプロダクションは不要です。一度の生成で、完成度の高い映像叙事が実現し、複雑な視聴覚表現をすべてのクリエイターの手の届くものにします
|
2)世界初 画像からの動画生成+エレメント参照:視覚の核心をロック、主役は常に一貫
基盤モデルによるマルチモーダル特徴の深層理解により、画像からの動画生成に加えて、複数の画像/動画によるエレメントを追加参照し、画面上の特定要素を二次的に固定することが可能です。これにより、モデルはプロのキャスティングディレクターのように、主役、小道具、シーンの特徴をしっかりとロックします。カメラがどのように動いても、視覚的主体は常に安定して一貫しています。
|
3)オールインワン音声・映像:役割ごとの発話制御、言語の壁を越えた混合発話
音声と映像の同期能力が大幅にアップグレードされ、テキストと視覚的な役割の精密なマッピングを実現。複数人物が同フレーム内にいる場合、誰に、どのセリフを話させるかも自在に制御でき、指示の混乱を根本的に解決します。
さらに、多言語(中・英・日・韓・西)及び各地の方言・アクセントでの演技、さらには複数言語の混合発話にも対応します。ビジネスシーンでのバイリンガル切り替えも、日常的な方言の掛け合いも、口元と表情は自然で流暢、違和感はありません。
4)ネイティブ級の文字表現:字形が精密、情報はロスレス
原画像の看板や字幕のディテールを保持する場合も、全新規の文字コンテンツを生成する場合も、モデルは文字がくっきりと、構造が厳密であることを保証します。動画の物理的なリアリティを高めるだけでなく、EC広告など多様なシーンにおける文字情報の高精度なニーズに直接応えます。
5)15秒の長時間生成:時間制限を突破、尺と想像力が同期
新バージョンでは最大15秒の連続動画生成が可能になり、3〜15秒の柔軟な長さ指定もサポートします。これは単なる尺の延長ではなく、叙事次元の再構築です。15秒という時間枠の中で、モデルはより複雑な動作ロジックと環境の変化を余裕を持って収めることができます。ロングテイクの細やかな展開も、複数のプロットの起伏も、一つの生成サイクル内で完全に表現可能になり、断片化したつなぎ合わせに別れを告げ、物語に本当の「起承転結」をもたらします。
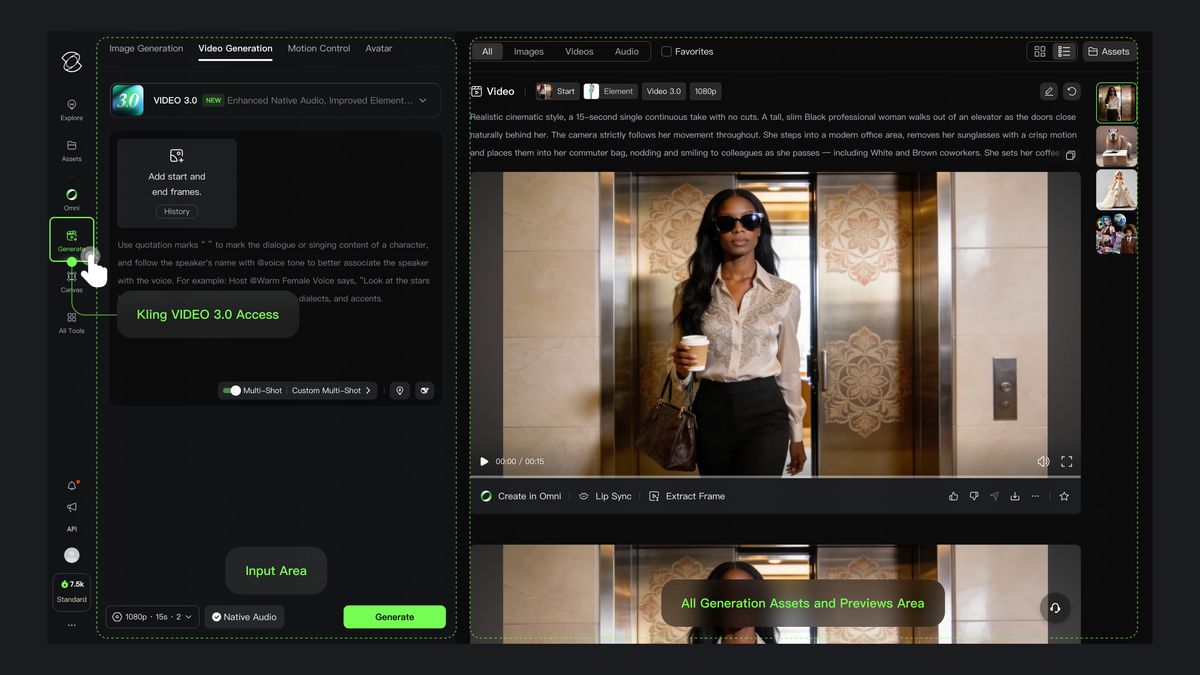
Kling動画 3.0 新機能の使い方
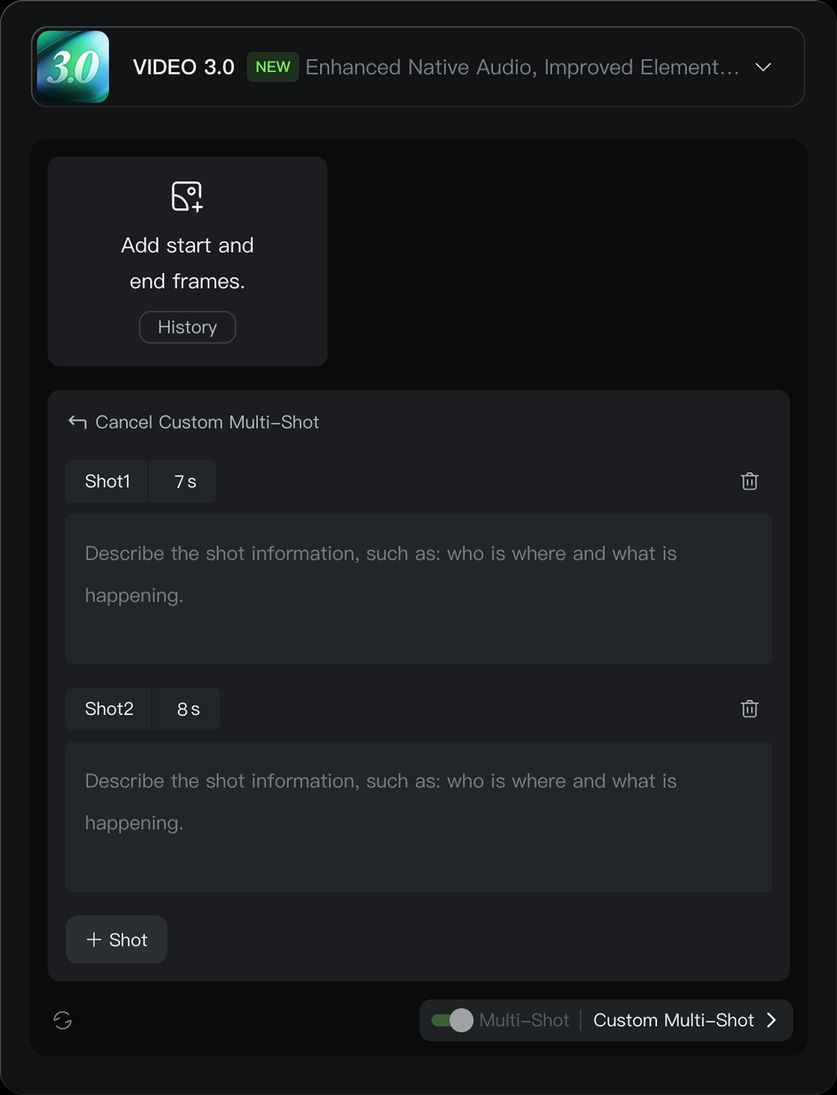
1)マルチカットによるストーリーテリング
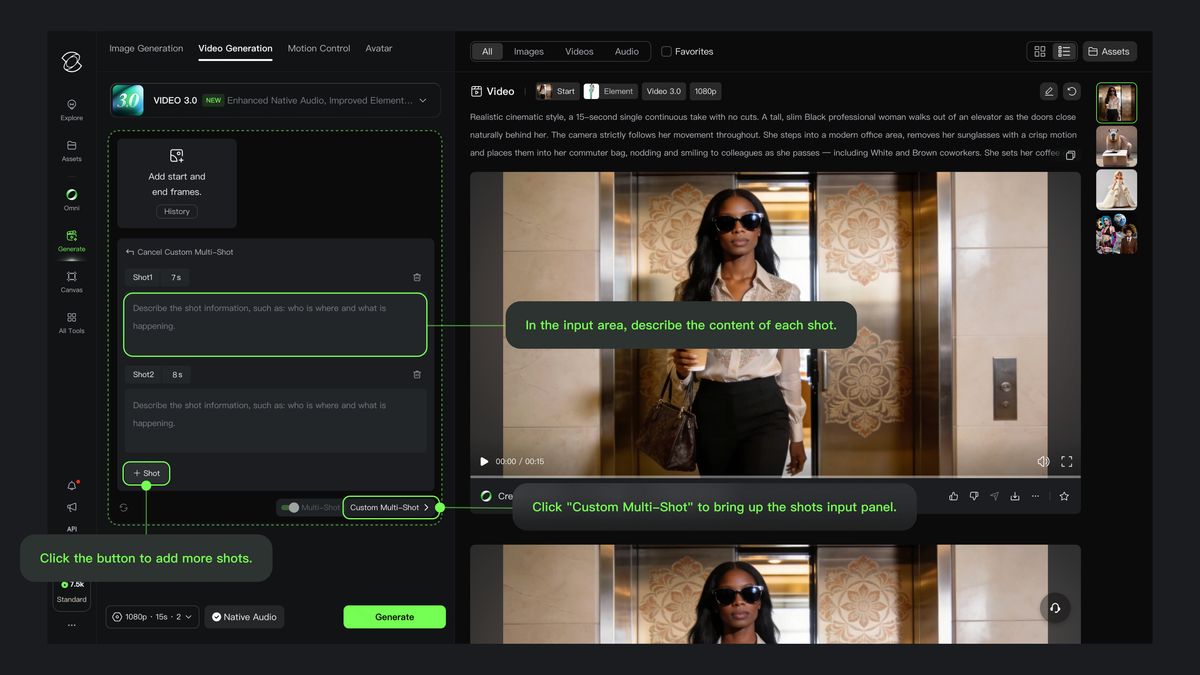
動画 3.0 では、高度に柔軟なカット割り制御能力が新たに追加され、画角とカメラポジションを柔軟にコントロールして、動画の叙事効果を高めることが可能となりました。動画 3.0 では、「スマートカット割り」 と 「カスタムカット割り」 の2つの方法で、マルチカット動画の生成を開始できます。「スマートカット割り」をオンにすると、モデルが自動的に動画のカット切り替えを計画します。このスイッチは、「カスタムカット割り」を有効にするための前提条件となります。「スマートカット割り」をオフにすると、デフォルトで単一カットのコンテンツが出力されます。
「スマートカット割り」スイッチをオン | 「カスタムカット割り」をクリックしてカット内容を設定 |
「スマートカット割り」機能をオンにすると、モデルが自動でカット切り替えを計画し、マルチシーン動画を生成します。手動での記述は不要です。 | 各カットの具体的な内容を設定したい場合は、「カスタムカット割り」をクリックし、カット数や各カットの長さを柔軟に設定できます。 |
|
|
スマートカット割り
動画 3.0 の入力エリアにある「スマートカット割り」スイッチをオンにした状態で、動画 3.0 は指示に基づいて動画のシーン転換、画角スケジューリング、カメラポジション切り替えを自動で計画します。「スマートカット割り」スイッチがオンの場合、ほとんどの場合モデルは指示に従いますが、指示内容が単一カットでの表現により適していると判断した場合、モデルは実際の状況に応じて柔軟に対処します:
Prompt | 画像 | 動画 |
ヨーロッパの別荘の屋外テラスシーン。青白チェックのテーブルクロスをかけたダイニングテーブルのそばに、青白ストライプの半袖シャツにカーキ色のショートパンツ、茶色のベルトをした若い白人女性が裸足で座っている。向かいは白いTシャツの若い白人男性。カメラがズームインし、女性はグラスの中のジュースを揺らしながら、遠くの林を見つめて言う。「These trees will turn yellow in a month, won't they?」。男性のクローズアップ、うつむきながら言う。「but they'll be green again next summer.」。そして女性が振り返り、向かいの男性を見て笑いながら言う。「Are you always this optimistic? Or just about summer?」。そして男性が顔を上げ、女性を見つめて言う。「Only about summers with you.」 |
| 
|
中年の男性が西洋料理店で注文をしており、インド訛りの英語で言う:「excuse me, I would like to order a seafood pasta, and a filet mignon. medium-rare」。頭を上げて続けて言う:「And, do you have any drink recommendations?」 |
|
|


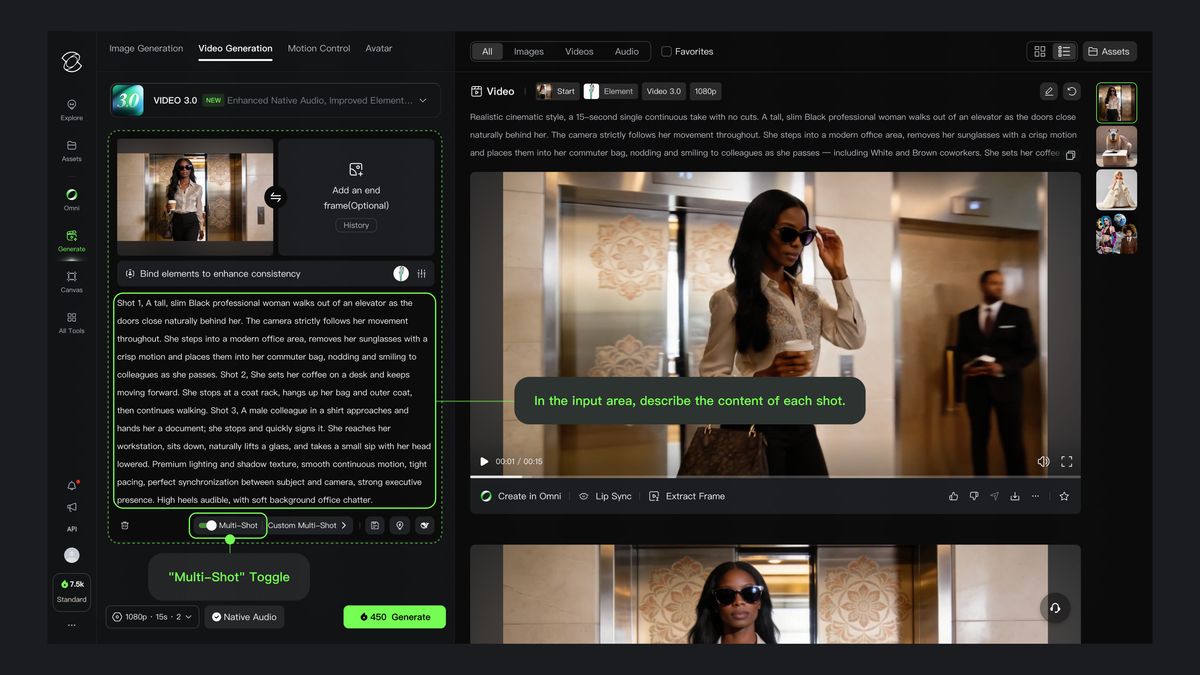
カスタムカット割り
「スマートカット割り」スイッチをオンにした状態で、「カスタムカット割り」をクリックすると、各カットの内容や長さを精密に制御でき、モデルは指示に厳密に従い、期待通りのマルチカット動画を生成します:
Prompt | 画像 | 動画 |
カット1:黒人男性がトラックを運転している横顔のカット。シネマティックなハンドヘルド撮影。 カット2:黒人男性がトラックを運転している正面のマクロショット。シネマティックなハンドヘルド撮影。 カット3:ハンドルを握る手元のマクロショット。シネマティックなハンドヘルド撮影。 カット4:助手席に置かれた、年季の入った若い黒人の子どもの写真のマクロショット。シネマティックなハンドヘルド撮影。 |
Kling AI クリエイティブパートナープログラム(CPP)@Dave Clark より | |
カット1: 低角度の後方ワイドショット。ライダーを追いかけながら前方へ走行する。 カット2: 低角度の横からのクローズアップ。バイクの車輪を強調したカット。 カット3: ライダーの一人称主観視点。前方にハンドルとメーターが見える。 カット4: 正面からのミディアムショット。バイクを迎え撃つように後退しながら追従し、ヘルメットがカメラ正面を向く。 カット5: 横位置・アイレベルのトラッキングショット。わずかにカメラが並走移動する。 カット6: 高所からのやや俯瞰のワイドショット。カメラが上昇しながら、スノーモービルが雪原の奥へ進み、純白の雪面に蛇行する轍を描く。両側には雪に覆われた森が点在する。 |
|
|

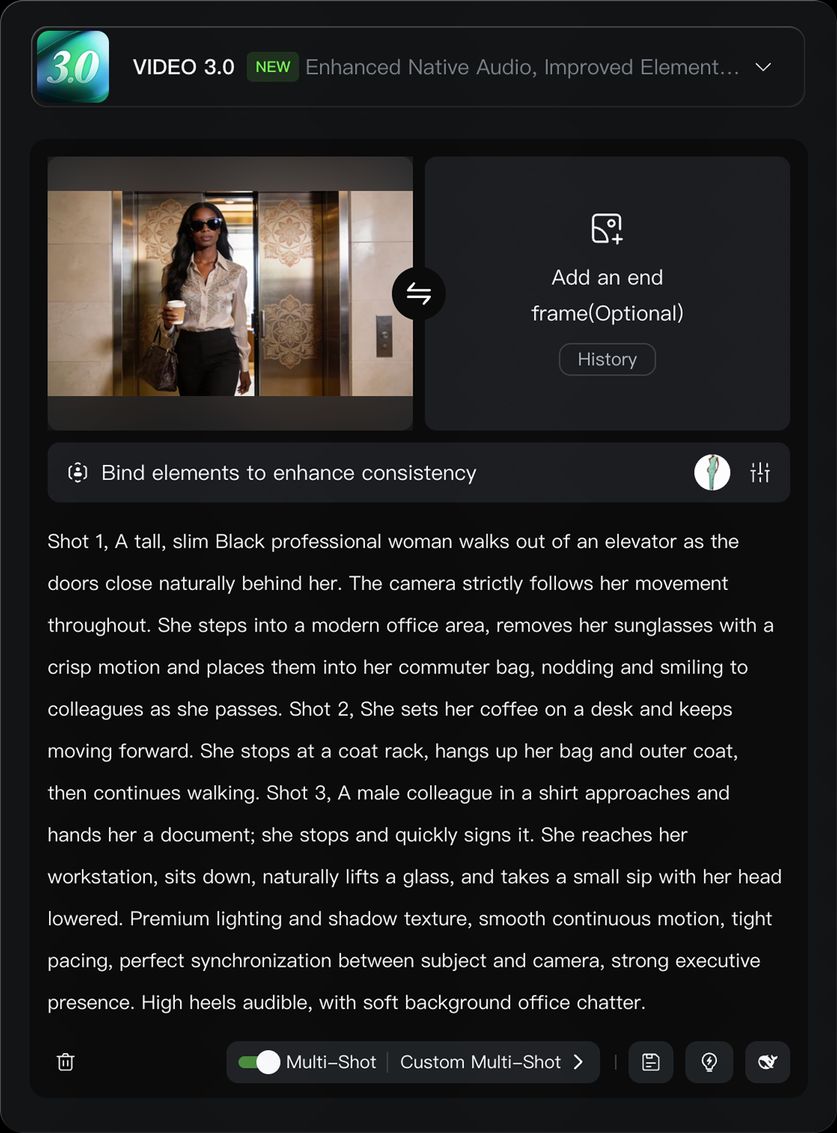
2)画像からの動画生成 + エレメント参照
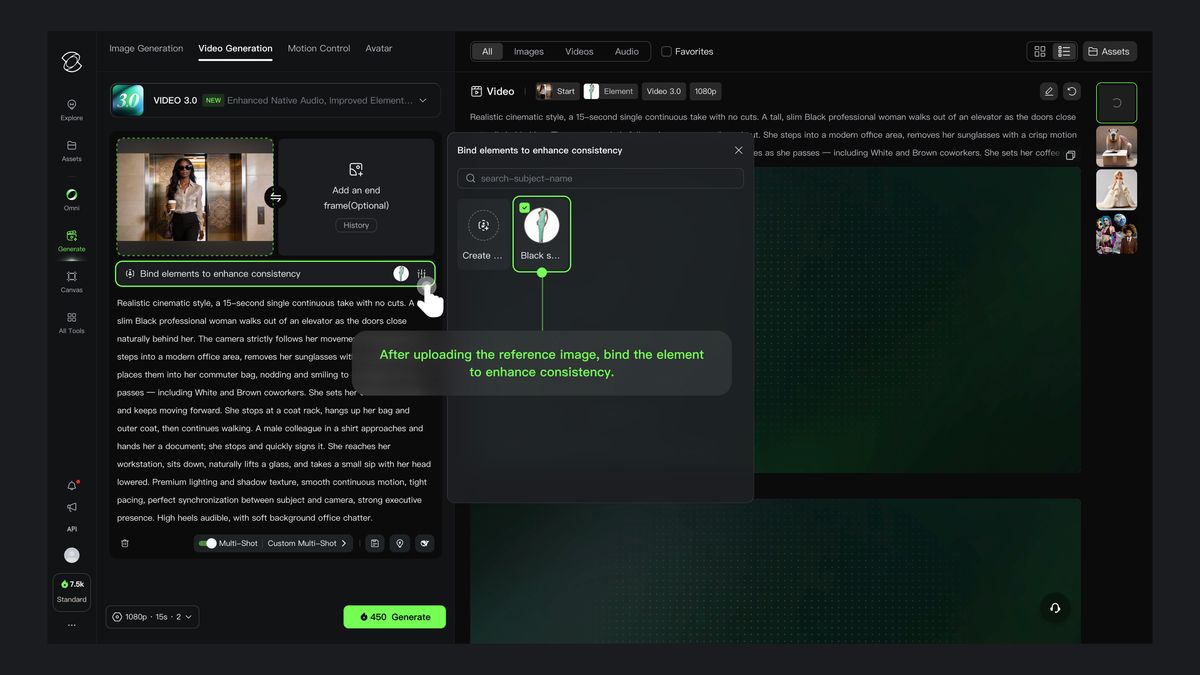
動画 3.0 では、画像からの動画生成機能に加え、エレメントを固定する能力が追加され、画面上の特定要素をロックして、主役が最初から最後まで一貫していることを保証できます。カメラがズームやパン、トラックなどをしても、エレメントは明確に安定し、ずれたり見失ったりすることはありません。
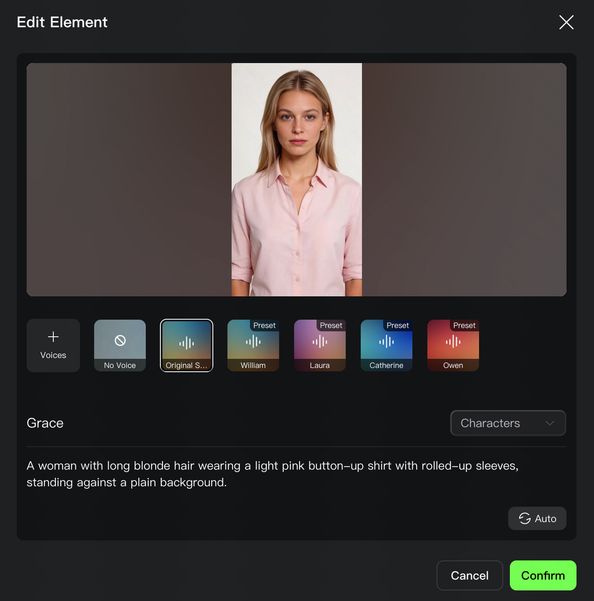
画像をアップロード後、「エレメントをバインド、一貫性を強化」エントリーから作成済みのエレメントをバインドすると、エレメント参照機能を利用して、エレメントがロックされ、画面が安定した動画を生成できます。エレメントのバインドは、エレメントの外見と音色の両方の一貫性を同時に実現します:視覚的にはエレメントの特徴に精密にマッチし、音色はエレメント作成時に事前にバインド可能です。すでに音色がバインドされたエレメントを選択した場合、 prompt 内で追加で音色を設定することは推奨されません。
Prompt | 画像 | エレメント参照画像 | 動画 |
リアルなオフィス環境の質感。ロングテイク、カットなしのワンシーンワンショット、全編を通して中景で職場の女性を安定して追跡。カメラは人物と同期して移動:人物が歩くときはカメラも同時に追跡、人物が止まるとカメラも即座に静止。動作は自然で連続、カメラワークは流暢。女性がエレベーターから前進して出て行き、背後でエレベーターのドアがゆっくり自然に閉まる。オフィスエリアに入り、手でサングラスを外し、さっと通勤カバンに入れる。すれ違いざまに同僚に自然にうなずいて挨拶する。彼女が一時停止すると、カメラも同時に静止。通勤カバンをオフィスエリアのコートハンガーに掛け、次に上着を脱いで同じハンガーに掛ける。服を掛けた後、再び前進し、カメラも同時に追跡。フォーマルなシャツを着た男性が正面から歩いてきて、書類と署名ペンを渡す。彼女が停止し、カメラも同時に静止。受け取って書類に署名する。署名後、再び前進し、カメラも同時に追跡。最終的に彼女はデスクのそばに歩いて行き、椅子のそばに座り、手を伸ばしてデスク上の一杯の茶を取り、うつむきながら一口すする。動作はリラックスして自然。 |
|
|
|
カメラは徐々に少女の正面へと回り込み、少女は顔を上げ、何年ぶりかに再会した旧友を見つけたかのように、カメラに向かって温かく微笑む。 |
|
| 初フレーム+エレメントによる一貫性強化の生成結果
初フレームのみの生成結果
|








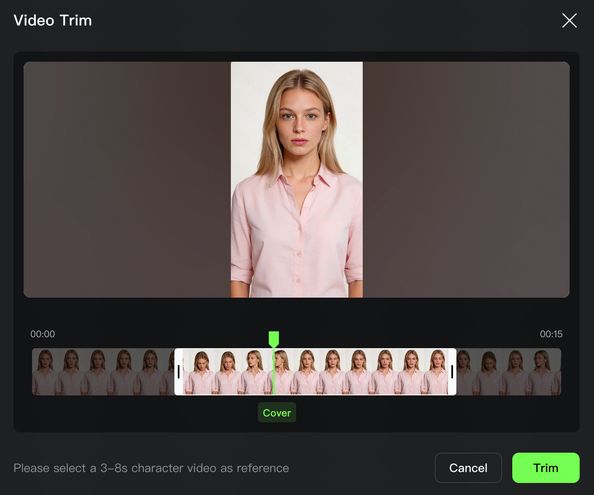
- エレメントの作成方法は2種類:①人物動画をアップロード/録画:システムが自動的にキャラクターの外見とネイティブ音声を抽出し、原音声を保持するか、カスタム音声に置き換えることが可能です。②2〜4枚のエレメント参照画像をアップロード:キャラクタータイプのエレメントには音声ファイルをアップロードするか、音色を指定して専用の声を定義できます(詳細は👉3.0 Omni 主体库使用指南)。
動画を録画してキャラクターエレメントを作成(アプリ版のみ対応) | ||
キャラクター動画の撮影をクリックし、録画セッションに入り、動画エレメントの作成を開始 | インターフェースの指示に従って音声録音と多角度撮影を完了 | エレメントの音色、名前、説明などの情報を完成させ、動画キャラクターエレメントの作成を完了 |
|
|
|
動画をアップロードしてキャラクターエレメントを作成 | ||
動画をアップロードし、エレメント作成を開始 | 動画を適切な長さにトリミング(多角度のキャラクター情報を含むシーンを推奨) | エレメントの音色、名前、説明などの情報を完成させ、動画キャラクターエレメントの作成を完了 |
|
|
|
キャラクター型(複数画像)エレメントに音色をバインド | ||
| ||
| ||





3) 音声・映像同時生成
動画 3.0 は、音声と映像の同期能力を全面的にアップグレードし、従来の基盤の上でテキストと役割の精密なマッピングを実現し、複数人物の指示精度を大幅に向上させると同時に、多言語、多方言及びアクセントの演技をサポートし、言語表現の境界を打ち破り、音声と映像の連動をより自然で多様なものにします。
複数役割の指示
Prompt内で各役割のセリフ内容を明確にすると、 3.0 モデルは自動的に役割とセリフの対応関係を解析し、複数役割の指示混乱問題を簡単に解決し、複数人物同フレーム内での指向性発話を実現します。指示を入力する際、人物の描写と対応する発話内容を対応付けて記述できます。動画 2.6 モデルと比較して、 3.0 モデルは3人以上の複数役割指示をうまくこなし、より優れた叙事効果を実現します。
Prompt | 画像 | 動画 |
家庭内の室内シーン。背景にはリビングのエアコンのかすかな送風音があり、日常的でリアルな雰囲気。母(小声で感慨深く、驚いた口調):“Wow, I didn’t expect this plot at all.” 父(低めの声で淡々と相づちを打つ):“Yeah, it’s totally unexpected, never thought that would happen.” 男の子(弾んだ声で):“It’s the best twist ever!” 女の子(うなずきながら、興奮した口調で):“I can’t believe they did that!” |
|
|

多言語コンテンツ生成
動画 3.0 は、中・英・日・韓・西の5言語のセリフ出力をサポートし、単一動画内でも複数言語の混合演技が可能です。対応するテキストを入力すると、モデルは自動的に発音をマッチングし、多言語のシームレスな切り替えを実現します。もし役割のセリフが上記目標言語以外のテキストで入力された場合、モデルは自動的にセリフを英語に翻訳して出力します。
Prompt | 画像 | 動画 |
朝もやの小さな駅で、男の子は笑いながら弁当を差し出した:「急いで作ったけど、大丈夫? お母さんのレシピだよ。」 女の子は笑顔で受け取った:「うん、きっと美味しい! 到着したら LINE するね。」
|
|
|
韓国の高校の屋上、遠くに都市の明かりが見え、そよ風が吹く中、夜空には星がきらめいていた。女の子は手すりにもたれてぼんやりしている。男の子はコーラを2缶持って歩いてきて、女の子に差し出した。女の子はコーラを受け取り、開けた。 男の子(軽い口調、韓国語): 「숙제 다 했어? 왜 여기 있어?」 女の子(ため息、韓国語): 「시험이 너무 무서워.」 男の子(優しく、韓国語): 「걱정 마, 넌 잘할 거야.」
|
|
|
カメラは二人のやり取りに焦点を当てた。貴婦人の目は穏やかで、侍女は頭を少し下げて耳を傾けていた。貴婦人は手を上げてそっと袖をなで、柔らかい口調で話した:「오늘 후원에서 피어난 꽃을 보니, 시원한 바람이 분다. 너도 함께 걸어볼까?」 侍女は少し体を前に傾け、敬意を込めて答えた:「네, 아씨님. 따라갈게요.」
|
|
|
マドリードの古い街に陽光が降り注ぐ。街角のパン屋の前で、中国人観光客の女の子と灰色のフーディーを着た男の子が店員の方へ歩いていく。二人とも礼儀正しい笑顔を浮かべていた。 女の子観光客(ややゆっくり、拙いアクセントで、スペイン語):「Disculpe, ¿dónde está la plaza mayor?」 白髪のスペイン人店員(横を向き、前方を指さしながら、明るい口調で、スペイン語):「Por allí, a dos calles. Muy cerca.」 女の子観光客はうなずいて礼をし、男の子観光客も同意してうなずく(スペイン語):「Muchas gracias.」 店員は微笑みうなずき、二人は指示された方向へ歩き出した。 |
|
|




方言・アクセントコンテンツ生成
Prompt内で主体が使用する方言やアクセントを注記すると、モデルは役割の語気やイントネーションを再現し、地元の方言やアクセントの演技を実現します。
現在、動画 3.0 は既に、中国語(例えば東北なまり、北京なまり、台湾なまり、広東語、四川語など)と英語(アメリカアクセント、イギリスアクセント、インドアクセントなど)の方言や特定のアクセントのコンテンツ生成を比較的うまくサポートしています。指定された発話内容部分で、生成を希望するアクセントや方言のタイプを注記するだけです。
Prompt | 画像 | 動画 |
高層オフィスビルの中で、男性は体を後ろに傾け、疲れたような、少し嫌悪の混じった表情で、広東語で言った: 「其实……我真系唔系好 buy 你呢个 logic 啰。成个 proposal 根本 align 唔到我哋个 core value。你个 flow 咁乱,点样去 convince 个 client 呀?不如你返去 re-think 下个 angle,听朝早我要见到个 final version。」
|
|
|

4)ネイティブ文字能力
動画 3.0 モデルはネイティブ文字能力を追加し、原画像の文字ディテールを精密に保持し、EC広告、クリエイティブショートドラマなど様々な創作シーンに適応し、多様化する創作ニーズを満たします。モデルはアップロードされた画像内の文字コンテンツ(看板、字幕、標識など)を自動認識し、文字の一貫性を保持し、文字のずれやぼやけを効果的に回避し、情報の完全な表現を保証します。
Prompt | 画像 | 動画 |
パリのアパルトマンの窓辺のシーン。背景には柔らかなフランス風ピアノBGMが流れる。午後の黄金の光がブラインド越しに香水瓶に差し込み、斑模様の光を作り出している。カメラは散らばったバラの花びらからゆっくりと寄り、Kling香水瓶のカット面に焦点を合わせる。 ナレーション(怠惰なフランス女性の声、イギリスアクセント、ゆったりとした語り): 「Bathe in the golden hour.」カメラは香水瓶をスローモーションで回り、金色の刻印と瓶身に映る光の流れを捉える。ナレーション: 「Kling, a whisper of Parisian elegance.」カメラが引いて全体のシーンを映す — 香水瓶はベルベットの台座に置かれ、窓の外にはパリの建物がほのかに見える。 ナレーション: 「Wrap yourself in luxury with every breath.」
|
|
|
カメラ画面は常にバットに刻まれた「KLING」にフォーカスし、選手が野球ボールを打撃する瞬間を捉える。
|
|
|


5)15秒 ロングテイク生成
動画 3.0 は15秒のロングテイク動画生成能力を開放し、同時に3〜15秒の柔軟な長さ調整をサポートし、より複雑な動作ロジックとプロット変化を収容し、物語の「起承転結」を完全に表現します。断片化した動画のつなぎ合わせに別れを告げ、創作効率と作品の一貫性を向上させます。
Prompt | 画像 | 動画 |
超広角中ロングショット横向きトラッキングでオープニング。スタビライザーは低く地面すれすれに移動。冷たい青の夜景と銀白の星空が高コントラストのロマンティックな映画調を形成し、強い詩的リアリズムと古典的叙事詩的気質を帯びる。主体は濃い緑のロングドレスを着た若い女性。月明かりに照らされた庭の芝生を全力で走り、ドレスの裾が風に煽られて激しい動的曲線を形成する。右手は白い小花をしっかり握り、左手でドレスの裾を持ち上げる。呼吸は荒いが眼差しは固い。4秒目、カメラは彼女と共に前進加速し、背景には古風なドレスを着た男女多数が左右から次々に画面に乱入し、彼女と並走する。近づこうとする者も、振り返って叫ぶ者もいるが、誰一人として彼女に実際に触れることはない。追跡と逃避を暗示する。8秒目、カメラは徐々に中景に近づき、主役の前方にパンして追跡し、わずかに上昇する。彼女は振り返って背後にいる若い男性キャラクターを一瞬見つめ、二人の眼差しが走りながら交差する。感情が走りの中で爆発し、女性と男性は手をつないで一緒に走る。12秒目、音楽と動作がクライマックスに達する。カメラは彼女の横顔と舞い上がる髪にぴったり寄り添い前進する。彼女は白い花を手放し、空中に放り投げる。花はゆっくりと落下し、背後を走る群衆にかすめられる。最後の3秒、カメラは止まらず前進を続ける。女性と男性は群衆を抜け出し、庭の果ての星空に向かって走り、その姿は徐々に画面の中心を占める。全体の雰囲気は熱烈で、ロマンティックで決然としており、運命、選択、自由に関する爆発的な物語のようだ。 |
|
|
これは 15 秒の映画クラスロングテイク。ワンショットで編集やトランジションなし。舞台は光影がまだらな石膏像の塔内部で、周囲に巨大な白い石膏像が積み重なり、神秘的で重苦しい雰囲気が漂う。シーン開始時、主人公は激しい走りを終え、場の中心でピタッと停まり、胸を激しく起伏させ、茫然と無力な表情で瞳に恐怖が滲んでいる。カメラは主人公を中心に滑らかに 360 度旋回パンニング。カメラ回転中、主人公は慌てて四方を見回し叫ぶ:「Alex!Alex where are you!are you here?」 その後背景から愛らしい恐竜の鳴き声が響き、続いてカメラは主人公の肩越しにプッシュ。石膏柱の後ろから中小型の愛らしい小恐竜が歩き出し、愛らしい鳴き声を上げる。主人公は音に驚き振り返り、恐竜を見た瞬間号泣し、思い切り前に駆け寄ってしっかり抱き締める。恐竜はおとなしく主人公の胸に寄り添う。 主人公は泣きながら恐竜を優しくなで、震えながら話す:「I find you!Thanks for god,I‘m so scared!」 全体の光影は映画的な質感に満ち、感情は絶望から感動の極みの再会へと変化する。 |
|


動画 3.0 モデル 料金体系
動画 3.0 は「音声・映像同期」と「音声なし」の2つのモードを提供し、各モードは 1080p と 720p の2つの解像度をサポートします。そのうち、「音声・映像同期」モードでは、追加で音声制御機能を有効にすることができます。異なるモードに対応する動画サービス料金は秒単位で課金され、料金体系が異なります。
1080p | 720p | |
3.0 動画生成 - 音声・映像同期 | 12 クレジット/s | 9 クレジット/s |
3.0 動画生成 - 音声なし | 8 クレジット/s | 6 クレジット/s |
3.0 動画生成 - 音声制御 | 2 クレジット/s | 2 クレジット/s |
- 例1: 5 秒の 3.0 音声・映像同期 1080p 動画生成は 60 クレジット
- 例2: 5 秒の 3.0 音声なし 720p 動画生成は 30 クレジット
- 例3: 5 秒の 3.0 音声・映像同期+音声制御 1080p 動画生成は 70 クレジット







