클링 비디오 3.0 기능 업그레이드

能力项 | Kling 비디오 2.6 | Kling 비디오 3.0 | |
텍스트 투 비디오 | ✅ | ✅ | |
이미지 투 비디오 | ✅ | ✅ | |
스타트 엔드 프레임 투 비디오 | ✅ | ✅ | |
사운드&영상 동시 출력 | ✅ | ✅ | |
스마트 멀티 샷 | ❌ | ✅ | |
스타트 프레임 + 피사체 참 | ❌ | ✅ | |
3인 이상 지칭 제어 | ❌ | ✅ | |
다국어 (중·영·한·일·스페인) | ❌ | ✅ | |
방언, 악센트 | ❌ | ✅ | |
15초 생성 | ❌ | ✅ | |
자유로운 초 설정 | ❌ | ✅ | |
Kling 비디오 3.0 시리즈 모델 하이라이트
1) 스마트 멀티 샷:AI 감독의 등장, 원클릭으로 완성되는 시네마틱 감성
단일 컷의 나열은 끝났습니다. AI가 당신의 시나리오를 이해합니다. 새로운 스마트 멀티 샷 시스템은 프롬프트 속의 장면 전환을 예민하게 포착하여 숏 사이즈와 카메라 위치를 자동으로 조절합니다. 클래식한 투 샷 대화부터 스토리보드를 넘나드는 대사 연출, 내레이션까지 모든 고급 영상 언어를 모델이 정밀하게 구현합니다. 번거로운 후반 작업 없이 단 한 번의 생성만으로도 완성도 높은 영상 서사가 탄생하며, 복잡한 시청각 표현을 모든 크리에이터가 손쉽게 실현할 수 있습니다.
|
2) 세계 최초 이미지 투 비디오+주체 일관성 강화:고정된 비주얼 코어, 변치 않는 주인공
하위 모델의 멀티모달 특징에 대한 깊은 이해를 바탕으로, 이미지 투 비디오 생성 시 다중 이미지 주체 또는 비디오 주체를 추가로 삽입할 수 있습니다. 이를 통해 화면 내 특정 요소를 2차 앵커링함으로써, 모델이 마치 전문 캐스팅 디렉터처럼 주인공, 소품, 장면의 특징을 견고하게 고정합니다. 카메라가 어떻게 움직이고 줌이 변하더라도 시각적 주체는 처음부터 끝까지 흔들림 없이 유지됩니다.
|
3) 전능한 사운드&영상:캐릭터 맞춤형 구동, 경계 없는 다국어 지원
음성-영상 동기화 능력이 대폭 업그레이드되어 텍스트와 시각적 역할의 정확한 매핑을 실현했습니다. 여러 인물이 한 화면에 등장하는 상황에서, 원하는 사람이 원하는 타이밍에 말하게 할 수 있어 지칭 혼란 문제를 근본적으로 해결했습니다.
동시에 다국어(중국어, 영어, 일본어, 한국어, 스페인어) 및 지역 방언과 억양의 자연스러운 표현을 지원하며, 심지어 여러 언어를 혼합해서 말하는 것도 가능합니다. 직장에서의 이중 언어 전환부터 일상적인 방언 대화에 이르기까지, 입 모양과 표정이 모두 자연스럽고 매끄러워 어색함이 전혀 없습니다.
4) 네이티브급 텍스트: 정교한 글자, 무손실 정보 전달
원본 이미지 속의 간판이나 자막 디테일을 보존하는 것은 물론, 완전히 새로운 텍스트 콘텐츠를 생성할 때도 모델은 선명한 글자체와 엄격한 구조를 보장합니다. 이는 비디오의 물리적 사실감을 높여줄 뿐만 아니라, 이커머스 광고 등 텍스트 정보의 고정밀도가 요구되는 다양한 비즈니스 환경의 니즈를 즉각적으로 충족시킵니다.
5)15초 초장길이 생성:시간의 한계를 넘어, 길이와 상상력이 동기화되다
새로운 버전에서는 최대 15초의 연속 비디오 생성이 가능하며, 3~15초 사이에서 자유롭게 길이를 설정할 수 있습니다. 이는 단순히 물리적 시간이 늘어난 것을 넘어 '서사적 차원의 재구성'을 의미합니다. 15초의 충분한 시간 안에서 모델은 더욱 복잡한 동작 논리와 환경 변화를 여유롭게 담아냅니다. 롱테이크의 섬세한 묘사부터 다층적인 플롯의 기승전결까지 하나의 생성 주기 내에서 완벽하게 구현하며, 조각난 영상들을 이어 붙이는 번거로움 없이 스토리의 진정한 완결성을 제공합니다.
클링 비디오 3.0 신 기능 사용 설명
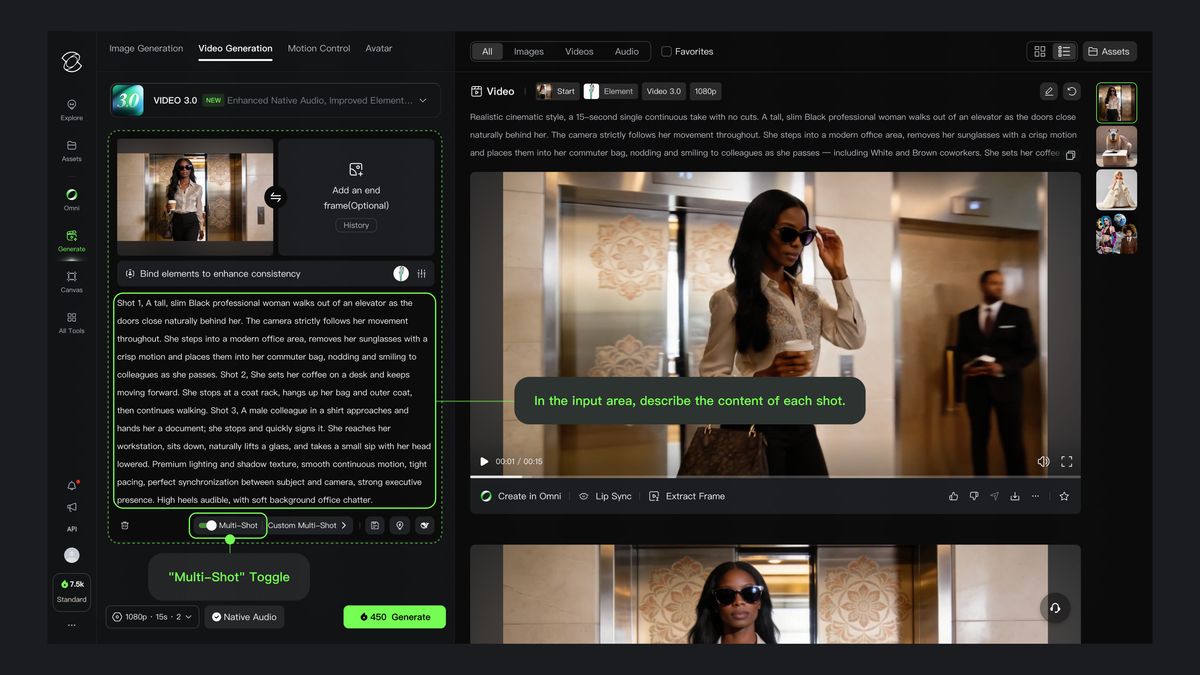
1)멀티 앵글 스토리텔링
비디오 3.0은 고도로 유연한 샷 제어 능력을 새롭게 추가하여, 시각적 범위와 카메라 위치를 유연하게 조정할 수 있어 비디오의 서사 효과를 향상시킵니다. 비디오 3.0에서는 「스마트 샷」과 「커스텀 샷」 두 가지 방식으로 멀티 샷 비디오 생성을 트리거할 수 있습니다.
「스마트 샷'을 활성화하면 모델이 비디오의 씬 전환을 자동으로 계획하며, 이 스위치는 「커스텀 샷」을 사용하기 위한 필수 선행 조건입니다. 「스마트 샷」을 비활성화하면 기본적으로 싱글 샷 콘텐츠가 출력됩니다.
「스마트 샷」스위치를 켜 주세요 | 「커스텀 샷(Custom Shot)」 설정 안내 |
「스마트 샷」 기능을 활성화하면, 모델이 자동으로 렌즈 전환을 계획하고 다중 장면 비디오 콘텐츠를 생성하므로 수동으로 설명할 필요가 없습니다. | 각 샷에 구체적인 내용을 설정하려면「커스텀 샷」을 클릭하여 샷의 개수와 각 샷의 지속 시간을 유연하게 구성할 수 있습니다. |
|
|
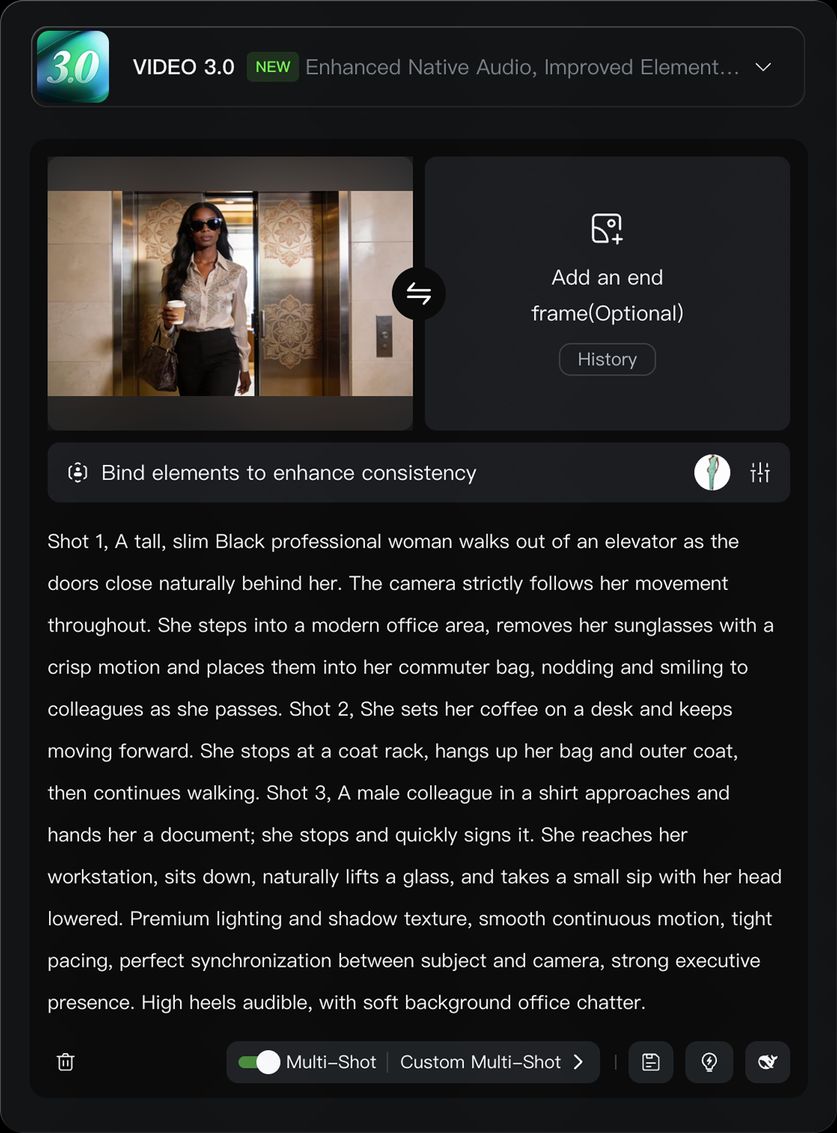
스마트 샷
비디오 3.0 입력 구역의 「스마트 샷」스위치를 켠 상태에서는, 비디오 3.0이 지시에 따라 자동으로 비디오의 장면 전환, 샷 배정 및 카메라 위치 전환을 계획합니다. 「스마트 샷」스위치가 켜져 있을 때 대부분의 경우 모델은 지시를 따르지만, 만약 지시에 설명된 장면이 단일 샷으로 표현하는 것이 더 적합한 경우 모델은 실제 상황에 따라 유연하게 대처합니다.
Prompt | 이미지 | 비디오 |
유럽 빌라 야외 테라스 장면, 파란색과 흰색 체크 무늬 식탁보가 깔린 식탁 옆에, 젊은 백인 여성이 파란색과 흰색 줄무늬 반팔 셔츠와 카키색 반바지를 입고 갈색 벨트를 매고 맨발로 앉아 있습니다. 맞은편에는 흰색 티셔츠를 입은 젊은 백인 남성이 앉아 있습니다. 카메라가 클로즈업되며, 여성이 유리잔 속 주스를 살짝 흔들며, 시선은 먼 숲을 향하고, 이렇게 말합니다: “These trees will turn yellow in a month, won’t they?” 카메라가 남성 얼굴로 바뀌며, 그는 고개를 숙인 채 말합니다: “But they’ll be green again next summer.” 그러자 여성이 고개를 돌려 맞은편 남성을 바라보며 미소 지으며 말합니다: “Are you always this optimistic? Or just about summer?” 남성이 고개를 들어 여자를 바라보며 말합니다: “Only about summers with you.” |
|  |
중년 남성이 양식당에서 음식을 주문하며 인도 억양의 영어로 말한다: "excuse me, I would like to order a seafood pasta, and a filet mignon. medium-rare". 고개를 들고 이어 말한다: "And, do you have any drink recommendations?" |
|
|


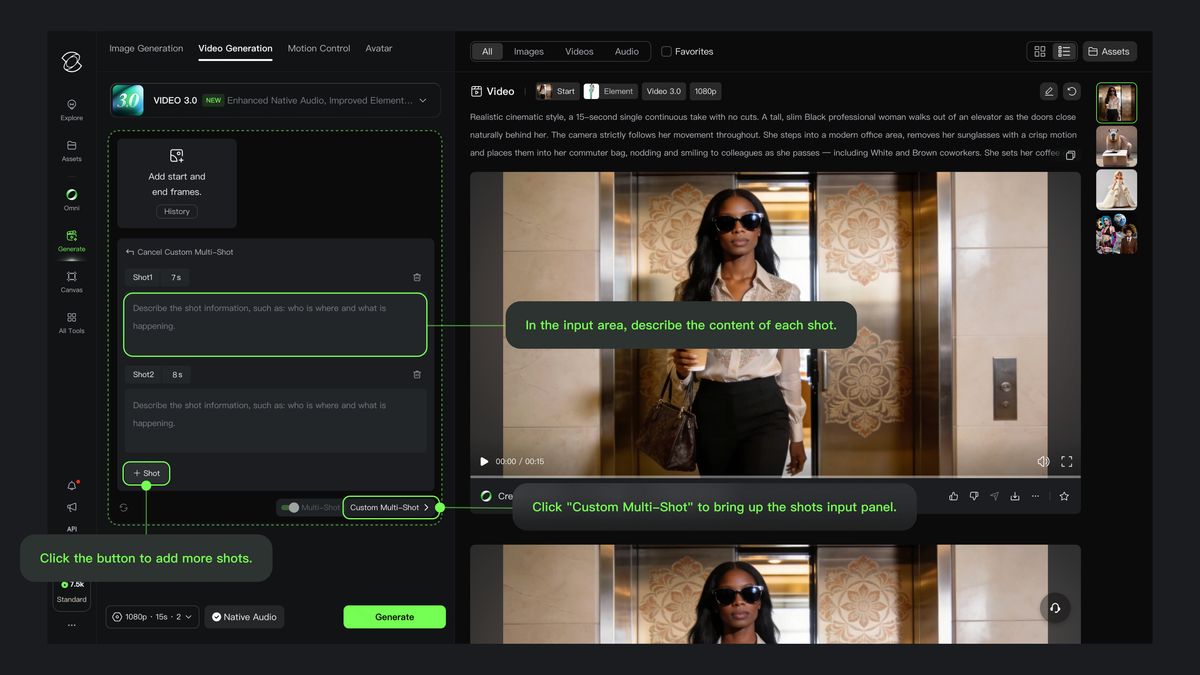
커스텀 샷
「스마트 샷」스위치를 켠 상태에서 「커스텀 샷」을 클릭하면, 각 샷의 내용과 지속 시간을 정밀하게 제어할 수 있으며, 모델은 지시에 엄격히 따라 예상에 부합하는 다중 샷 비디오를 생성합니다.
Prompt | 이미지 | 비디오 |
shot 1, profile shot of black man driving a truck, cinematic handheld
ショット1:黒人男性がトラックを運転している横顔のショット。シネマティックなハンドヘルド撮影。 ショット2:黒人男性がトラックを運転している正面のマクロショット。シネマティックなハンドヘルド撮影。 ショット3:ハンドルを握る手元のマクロショット。シネマティックなハンドヘルド撮影。 ショット4:助手席に置かれた、年季の入った若い黒人の子どもの写真のマクロショット。シネマティックなハンドヘルド撮影。 샷 1: 트럭을 운전하는 흑인 남성의 프로필 샷, 시네마틱 핸드헬드 샷 2: 트럭을 운전하는 흑인 남성의 정면 마크로 샷, 시네마틱 핸드헬드 샷 3: 핸들에 놓인 손의 마크로 샷, 시네마틱 핸드헬드 샷 4: 조수석에 놓인 젊은 흑인 아이의 낡은 사진 마크로 샷, 시네마틱 핸드헬드 |
| 클링 AI 크리에이티브 파트너(CPP) @Dave Clark |
샷 1: 낮은 앵글의 후방 와이드 샷. 라이더를 따라가며 앞으로 주행한다. 샷 2: 측면의 낮은 앵글 클로즈업. 오토바이 바퀴를 강조한 디테일 샷. 샷 3: 라이더의 1인칭 시점(POV). 전방에 핸들바와 계기판이 보인다. 샷 4: 정면 미디엄 샷. 오토바이를 마주 보며 뒤로 이동하는 트래킹 샷으로, 헬멧이 카메라를 정면으로 향한다. 샷 5: 측면 아이레벨 트래킹 샷. 카메라가 약간 병행 이동한다. 샷 6: 고공에서 내려다보는 와이드 샷. 카메라가 상승하며 스노모빌이 설원 깊숙이 달려가고, 새하얀 눈 위에 굽이치는 바퀴 자국이 남는다. 양옆에는 눈으로 덮인 숲이 흩어져 있다. |
| |
샷 1
|
| 클링 AI 크리에이티브 파트너(CPP) @希希叔叔 께서 제공 |


2)이미지 투 비디오 생성 + 주체 참조 기능
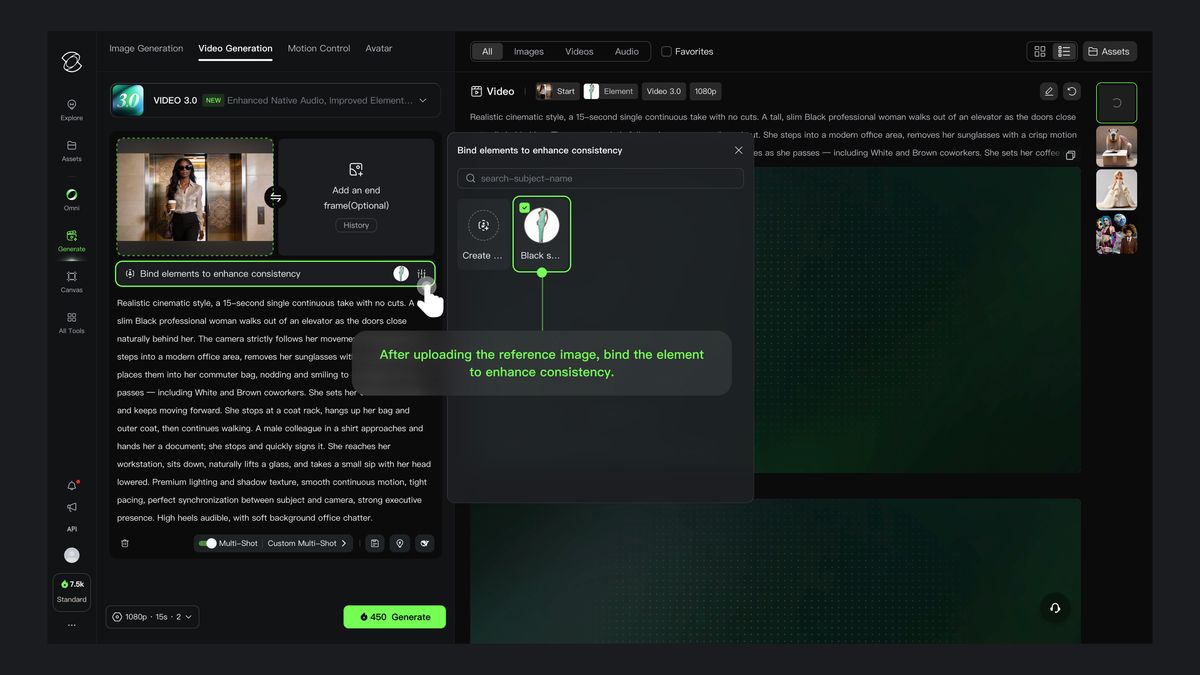
비디오 3.0은 이미지 투 비디오 생성 기능에 더해, 새로운 주체 바인딩 기능을 추가하여 화면의 특정 요소를 고정시키고 주인공이 처음부터 끝까지 일관되게 유지되도록 합니다. 카메라가 줌 인/아웃하거나 이동하더라도 주체는 선명하고 안정적으로 유지되며, 이탈하거나 사라지지 않습니다.
이미지를 업로드한 후, 「주체 바인딩, 일관성 강화」 메뉴를 통해 생성된 주체를 바인딩하면 주체 참조 기능을 활용하여 주체가 고정되고 화면이 안정된 비디오를 생성할 수 있습니다. 주체 바인딩은 주체의 외형과 음색의 이중 일관성을 동시에 실현할 수 있습니다: 시각적으로는 주체의 특징을 정확히 일치시키며, 음색은 주체 생성 시 미리 바인딩할 수 있습니다. 만약 음색이 이미 바인딩된 주체를 선택한 경우, 프롬프트에 별도로 음색을 설정하는 것은 권장되지 않습니다.
프롬프트 | 이미지 | 주체 참조 이미지 | 비디오 |
사실적인 직장 분위기, 롱 테이크 원 샷 무편집, 전 장면 미디엄 샷으로 직장 여성을 안정적으로 따라 촬영, 카메라와 인물이 동기화되어 움직임: 인물이 걸을 때 카메라는 동시에 따라가고, 인물이 멈출 때 카메라는 즉시 정지하여, 동작이 자연스럽고 연결되며, 카메라 움직임이 유연합니다. 여성이 앞으로 걸어 나와 엘리베이터를 빠져나오고, 뒤의 엘리베이터 문이 천천히 자연스럽게 닫힙니다. 그녀가 업무 구역으로 들어서며, 손으로 선글라스를 벗어 휴대한 출퇴근 가방에 넣고, 지나가며 마주치는 동료에게 자연스럽게 고개를 끄덕여 인사합니다. 그녀가 잠시 멈추자 카메라도 동시에 정지하며, 그녀가 출퇴근 가방을 업무 구역의 옷걸이에 걸고, 이어 외투를 벗어 같은 옷걸이에 겁니다. 옷을 걸고 난 후 그녀가 다시 앞으로 걸어가자 카메라도 동시에 따라갑니다. 정장 셔츠를 입은 남성 직원이 마주 걸어와 서류 한 부와 서명용 펜을 건네자, 그녀가 멈추고 카메라도 동시에 정지하며, 그녀가 서류를 받아 서명합니다. 서명을 마친 후 그녀가 다시 앞으로 걸어가자 카메라도 동시에 따라갑니다. 마지막으로 그녀가 사무실 책상 옆에 도착해 의자에 앉고, 손을 뻗어 책상 위의 차 한 잔을 들어 고개를 숙여 가볍게 한 모금 마시며, 동작이 느슨하고 자연스럽습니다. |
|
| |
카메라는 점차 소녀의 정면으로 이동하고, 소녀는 고개를 들어 여러 해 만에 만난 오랜 친구를 본 듯 카메라를 향해 따뜻하게 미소 짓는다. |
|
| 초기 프레임 및 객체 일관성 향상 생성 결과
초기 프레임 단독 생성 결과
|








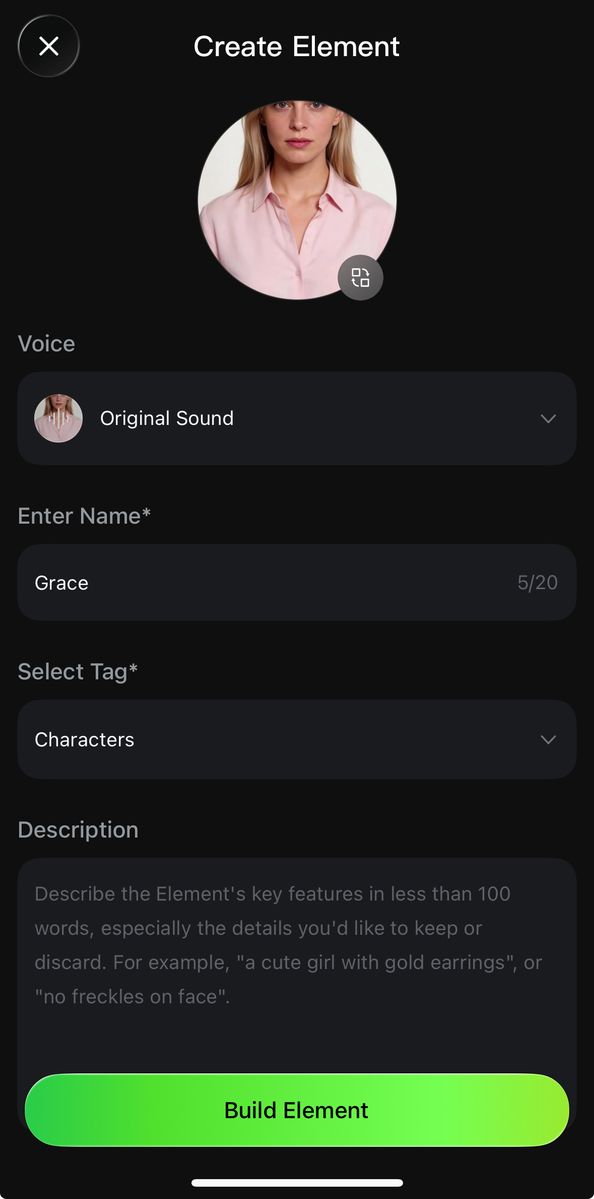
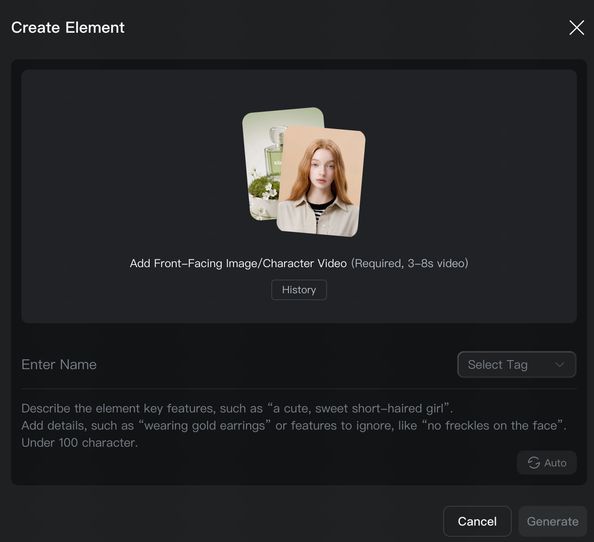
- 주체 생성은 두 가지 방법을 지원합니다. ① 인물 비디오 업로드 / 녹화: 시스템이 자동으로 캐릭터의 외형과 원본 음색을 추출합니다. 원본 음성 보존 또는 사용자 정의 음색으로 교체가 가능합니다.
② 2~4장의 주체 참조 이미지 업로드: 캐릭터 유형 주체의 경우 오디오 파일 업로드 또는 음색 지정이 가능하여 전용 음성을 정의할 수 있습니다.
비디오 녹화하여 캐릭터 주체 생성하기 (앱 버전에서만 지원됨) | ||
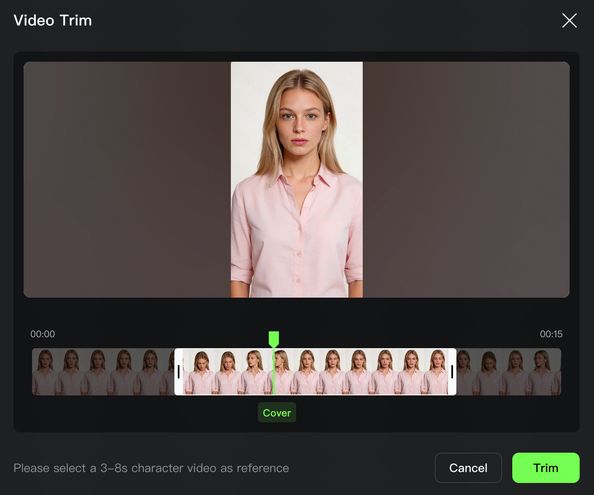
캐릭터 비디오 촬영 클릭 → 녹화 단계 진입 → 비디오 주체 생성 시작 | 인터페이스 안내에 따라 음성 녹음 및 다각도 촬영을 완료하세요. | 주체 음색, 이름, 설명 등의 정보를 완성하여 비디오 역할 주체 생성을 완료하세요. |
|
|
|
비디오 업로드를 통해 캐릭터 주체를 생성 | ||
비디오 업로드를 통해 주체 생성을 시작합니다. | 비디오를 적절한 길이로 편집하여, 다각도의 캐릭터 정보가 포함된 영상을 준비하세요. | 주체 음색, 이름, 설명 등의 정보를 완성하여 비디오 캐릭터 주체 생성을 완료하세요. |
|
|
|
캐릭터 유형 다중 이미지 주체에 음색을 바인딩 | ||
| ||
● 정면 참조 이미지를 업로드한 후, 캐릭터 유형 주체인 경우 음색 선택란이 나타납니다. ● 음색을 추출할 비디오를 업로드하거나, 기존 음색을 선택할 수 있습니다. ● 생성 완료 후 음색은 주체와 바인딩되며, 입력란에서 다시 음색을 지정할 필요가 없습니다. | ||





3)음성과 영상을 동시 생성
비디오 3.0이 음성-영상 동기화 능력을 전면 업그레이드합니다. 기존 기능을 기반으로 텍스트와 캐릭터의 정확한 매핑을 구현하여, 다중 인물 지시 정확도를 크게 향상시켰으며, 동시에 다중 언어, 다방언 및 악센트 연기를 지원하여 언어 표현의 경계를 허물고, 음성과 영상의 조화를 더욱 자연스럽고 다양하게 만들었습니다.
다중 캐릭터 지시 기능
프롬프트에 각 캐릭터의 대사 내용을 명확히 기재하면, 3.0 모델이 자동으로 캐릭터와 대사의 대응 관계를 분석하여, 다중 캐릭터 지시의 혼란 문제를 쉽게 해결하고, 다인 동시 발화를 정확하게 구현합니다. 지시 입력 시 인물에 대한 묘사와 해당 발화 내용을 대응하여 기술할 수 있습니다.
비디오 2.6 모델 대비 3.0 모델은 3인 이상의 다중 캐릭터 지시를 훨씬 효과적으로 수행할 수 있어, 더욱 뛰어난 서사적 효과를 실현합니다.
Prompt | 이미지 | 비디오 |
| 가정집 실내 환경. 배경에는 거실 에어컨에서 나는 은은한 바람 소리가 들리며, 현실적인 일상 분위기를 형성한다. 엄마(조용히 감탄하며, 놀란 어조):“Wow, I didn’t expect this plot at all.” 아빠(낮은 목소리로 담담하게 맞장구치며):“Yeah, it’s totally unexpected, never thought that would happen.” 소년(신이 난 어조로):“It’s the best twist ever!” 소녀(고개를 끄덕이며, 흥분한 어조로):“I can’t believe they did that!” |
| |
| 교실 안에 한 명의 여자 교사와 세 명의 학생이 서 있다. 카메라는 고정되어 있다. 여자 교사가 말한다: “我们不说,包的,但可以说”. 이후 화자가 교복을 입은 여학생으로 전환된다. 여학생은 한 손을 들어 주먹을 쥐고 말한다: “志在必得”. 그다음 화자가 첫 번째 남학생으로 전환된다. 남학생은 미소를 지으며 말한다: “万无一失”. 이어 화자가 가장 오른쪽에 서 있는 남학생으로 전환된다. 남학생은 두 손을 들고 말한다: “稳操胜券”. |
| |


다중 언어 콘텐츠 생성
비디오 3.0은 중국어, 영어, 일본어, 한국어, 스페인어 총 5개 언어의 대사 출력을 지원하며, 단일 비디오 내에서도 다중 언어 혼합 연기가 가능합니다. 해당 텍스트를 입력하면 모델이 자동으로 발음을 매칭하여 다중 언어 간 원활한 전환을 구현합니다. 만약 캐릭터 대사가 위 목표 언어 외의 텍스트로 입력된 경우, 모델은 자동으로 해당 대사를 영어로 번역하여 출력합니다.
프롬프트 | 이미지 | 비디오 |
아침 안개가 낀 작은 역에서, 남학생이 웃으며 도시락을 건넸다: 「急いで作ったけど、大丈夫? お母さんのレシピだよ。」 여학생은 웃으며 받아들였다: 「うん、きっと美味しい! 到着したら LINE するね。」
|
| |
한국 고등학교 옥상, 멀리 도시의 불빛이 보이고, 부드러운 바람이 불며, 밤하늘에는 별이 반짝였다. 여주인공은 난간에 기대어 멍하니 있었고, 남주인공은 콜라 두 캔을 들고 걸어와 그녀에게 하나를 건넸다. 여주인공은 콜라를 받아서 열었다. 남주인공 (편안하게, 한국어): 「숙제 다 했어? 왜 여기 있어?」 여주인공 (한숨, 한국어): 「시험이 너무 무서워.」 남주인공 (부드럽게, 한국어): 「걱정 마, 넌 잘할 거야.」
|
| |
카메라는 두 사람의 상호작용에 초점을 맞췄다. 귀부인의 눈빛은 온화했고, 시녀는 고개를 숙인 채 경청했다. 귀부인은 손을 들어 소매를 살짝 스치며 부드러운 목소리로 말했다: 「오늘 후원에서 피어난 꽃을 보니, 시원한 바람이 분다. 너도 함께 걸어볼까?」 시녀는 몸을 살짝 앞으로 기울이며 공손히 대답했다: 「네, 아씨님. 따라갈게요.」
|
| |
마드리드의 오래된 거리에 햇빛이 가득 비쳤다. 거리의 빵집 앞에서, 중국인 관광객인 여학생과 회색 후드티를 입은 남학생이 점원 쪽으로 걸어갔고, 두 사람은 공손한 미소를 지었다. 여학생 관광객 (조금 느리게, 서툰 억양으로, 스페인어): 「Disculpe, ¿dónde está la plaza mayor?」 백발 스페인 점원 (옆으로 몸을 돌리며 앞을 가리키며, 밝은 어조로, 스페인어): 「Por allí, a dos calles. Muy cerca.」 여학생 관광객은 고개를 끄덕이며 감사의 뜻을 전했고, 남학생 관광객도 함께 고개를 끄덕이며 동의 (스페인어): 「Muchas gracias.」 점원은 미소 지으며 고개를 끄덕였고, 두 사람은 안내된 방향으로 걸어갔다.
|
| |




방언, 악센트 콘텐츠 생성
프롬프트에서 주체가 사용하는 방언 또는 악센트를 명시하면, 모델이 캐릭터의 어조와 억양을 재현하여 진정한 방언과 악센트 연기를 구현할 수 있습니다.
현재 비디오 3.0은 다음과 같은 방언 및 특정 악센트 콘텐츠 생성을 비교적 잘 지원하고 있습니다:
중국어: 동북 방언, 베이징 방언, 대만 지역 방언, 광둥어, 쓰촨어 등
영어: 미국식 악센트, 영국식 악센트, 인도식 악센트 등
지정된 발화 내용 부분에 생성하고자 하는 악센트 또는 방언 유형을 표기하기만 하면 됩니다.
Prompt | 이미지 | 비디오 |
| 고정된 카메라 앞에서 젊은 바리스타가 고개를 숙이고 컵을 닦고 있다. 바리스타는 카메라를 올려다보며 쓰촨 사투리로 말했다: 「诶,你来了哇。今天喝点啥子嘞,冰美式还是拿铁。今天正好来了新豆子」 |
| |
고급 오피스 빌딩에서, 남자는 몸을 뒤로 기대고 피곤하고 약간 냉소적인 표정으로 광둥어로 말했다: 「其实……我真系唔系好 buy 你呢个 logic 啰。成个 proposal 根本 align 唔到我哋个 core value。你个 flow 咁乱,点样去 convince 个 client 呀?不如你返去 re-think 下个 angle,听朝早我要见到个 final version。」 |
| |


4)원본 텍스트 처리 능력
비디오 3.0 모델에 새롭게 추가된 원본 텍스트 처리 능력은, 원본 이미지의 텍스트 디테일을 정확하게 보존하며 전자상거래 광고, 창의적 단막극 등 다양한 제작 시나리오에 적합하여 다양한 제작 요구를 충족시킵니다. 모델은 업로드된 이미지 속 텍스트 내용(간판, 자막, 로고 등)을 자동으로 인식하고 텍스트 일관성을 유지하며 문자 위치 이탈이나 흐릿해짐을 효과적으로 방지하여 정보가 완전하게 전달되도록 보장합니다.
Prompt | 이미지 | 비디오 |
파리 아파트 창가 장면. 배경에는 부드러운 프렌치 피아노 BGM이 흐른다. 오후의 황금빛 햇살이 블라인드를 통해 향수병 위로 비치며 얼룩진 빛과 그림자를 만들어낸다. 카메라는 흩어진 장미꽃잎에서 천천히 접근하며 Kling 향수병의 컷팅 면에 초점을 맞춘다. 내레이션 (느긋한 프랑스 여성 목소리, 영국식 억양, 부드러운 속도): 「Bathe in the golden hour.」 카메라는 향수병을 슬로우 모션으로 돌며, 금빛 각인과 병 몸체 위로 흐르는 빛의 움직임을 포착한다. 내레이션: 「Kling, a whisper of Parisian elegance.」 카메라가 멀어지며 전체 장면을 고정 — 향수병은 벨벳 받침대 위에 서 있고, 창 밖으로 파리 건물이 희미하게 보인다. 내레이션: 「Wrap yourself in luxury with every breath.」 |
| |
카메라 화면은 언제나 야구방망이에 새겨진「KLING」에 초점을 맞추고, 선수가 야구공을 타격하는 순간을 담는다.
|
| |


5)15s 롱 테이크 생성
비디오 3.0이 15초 롱 테이크 비디오 생성 기능을 해금했습니다. 동시에 3-15초 유연한 길이 조절을 지원하여, 더 복잡한 동작 논리와 플롯 변화를 수용할 수 있으며, 이야기의 시작, 전개, 전환, 결말을 완전히 보여줍니다. 파편화된 비디오 조합에 작별을 고하고, 제작 효율성과 작품의 일관성을 향상시킵니다.
Prompt | 이미지 | 비디오 |
초광각 미디엄 롱샷 가로 팔로우 샷 오프닝, 스테디캠 저각 지면 접촉 이동, 차가운 파란 밤과 은백색 별빛이 높은 대비의 로맨틱 영화 색조를 형성하며, 강렬한 시적 리얼리즘과 고전 서사적 기질을 지님. 주체는 검은 녹색 긴 드레스를 입은 젊은 여성으로, 달빛에 비춰진 정원 잔디밭에서 전속력으로 달리고 있으며, 치마자락이 바람에 휘날려 격렬한 동적 곡선을 만들고, 오른손에는 하얀 꽃 한 송이를 꼭 쥐고 있고, 왼손으로 치마 자락을 잡아 올리며, 호흡은 거칠지만 시선은 단호함. 4초째, 카메라가 그녀를 따라 앞으로 가속하며, 배경에서 복수의 구시대 예복을 입은 남녀가 좌우에서 잇따라 화면 안으로 뛰어들어 그녀와 나란히 달리는데, 누군가는 접근하려 하고, 누군가는 뒤돌아 외치지만 아무도 실제로 그녀를 만지지 못해 쫓음과 도주를 암시함. 8초째, 카메라가 점차 미디엄 샷으로 줌 인해 주인공 전방으로 팬하며 약간 상승해 따라가고, 그녀가 잠시 뒤돌아 어린 남성 캐릭터를 바라보며 두 사람의 시선이 순간 교차하고, 감정이 질주 속에서 폭발하며, 여성과 남성이 손을 잡고 함께 뛰기 시작함. 12초째, 음악과 동작이 절정에 달하고, 카메라가 그녀의 측면 얼굴과 날리는 머리카락을 따라 전진하며, 그녀가 하얀 꽃을 손에서 놓아 공중으로 던지고, 꽃은 느린 속도로 떨어지며 뒤의 군중을 스쳐 지나감. 마지막 3초, 카메라는 멈추지 않고 계속 전진하며, 여성과 남성이 군중을 뚫고 정원 끝의 별빛을 향해 질주하며, 실루엣이 점차 화면 중심을 차지하고, 전체 분위기는 격렬하고 로맨틱하며 결연하게, 운명, 선택과 자유에 관한 폭발적 서사와 같음.
|
| |
이것은 15초 영화급 롱테이크로, 원샷 촬영으로 편집 및 전환 효과가 전혀 없다. 장면은 빛과 그림자가 얼룩덜룩한 석고상 탑 내부로, 주변에 거대한 흰색 석고상이 쌓여있고 신비롭고 압도적인 분위기가 감돈다. 장면 시작 시 주인공은 격렬한 달리기를 마치고 장면 중앙에서 갑자기 멈춰서 가슴을 힘겹게 오르내리고, 멍해지고 무력한 표정에 눈에는 공포가 가득하다. 카메라는 주인공을 중심으로 부드럽게 360도 회전 패닝 촬영한다. 카메라가 회전하는 동안 주인공은 조급하게 사방을 둘러보며 소리친다:「Alex!Alex where are you!are you here?」이후 배경에서 귀여운 공룡의 울음소리가 들리고, 이어 카메라는 주인공의 어깨 너머로 전진한다. 석고기둥 뒤에서 중소형의 귀여운 아기공룡이 걸어나와 귀여운 울음소리를 낸다. 주인공은 소리에 놀라 뒤를 돌고, 공룡을 본 순간 눈물을 터뜨리고, 아무것도 막지 못하고 앞으로 달려가 꽉 안는다. 공룡은 착하게 주인공 품에 기대는다. 주인공은 우는 가운데 공룡을 부드럽게 쓰다듬고, 떨며 말한다:「I find you!Thanks for god,I‘m so scared!」 전체적인 빛과 그림자는 영화적인 질감을 가지며, 감정은 절망에서 극도로 감동적인 재회로 전환된다. | |


비디오 3.0 모델 가격 정책
비디오 3.0은 "음성-영상 동기화"와 "음성-영상 비동기화" 두 가지 모드를 제공하며, 각 모드는 1080p 및 720p 두 가지 해상도를 지원합니다.
이 중 "음성-영상 동기화" 모드에서는 추가로 음색 제어 기능을 활성화할 수 있습니다. 다른 모드에 대응하는 비디오 서비스 요금은 초 단위로 과금되며, 요금 기준은 모드별로 차이가 있습니다.
1080p | 720p | |
비디오 3.0 생성 — 음성-영상 동기화 모드 | 12 크레딧/s | 9 크레딧/s |
비디오 3.0 생성 — 음성-영상 비동기화 모드 | 8 크레딧/s | 6 크레딧/s |
비디오 3.0 생성 — 음색 제어 기능 | 2 크레딧/s | 2 크레딧/s |
- 예시 1: 5초 길이의 3.0 음성-영상 동기화 1080p 비디오 생성은 60 크레딧
- 예시 2: 5초 길이의 3.0 음성-영상 비동기화 720p 비디오 생성은 30 크레딧
- 예시 3: 5초 길이의 3.0 음성-영상 동기화 + 음색 제어 1080p 비디오 생성은 70 크레딧







