Kling 動画 O1 は、世界初の統合型マルチモーダル動画モデルとして、全く新しい創作エンジンを提供し、無限のクリエイティブな可能性を解き放ちます。
Kling O1 は Multi-modal Visual Language (MVL) の理念に基づき、自然言語を意味の骨格とし、動画・画像・エレメンツ などのマルチモーダルな記述を組み合わせ、あなたの意図を正確に理解します。より直感的な操作で、より効率的な創作体験を実現します。
Kling 動画 O1 モデル五つの魅力
(1)万能エンジン:世界初の統一マルチモーダル動画大規模モデル
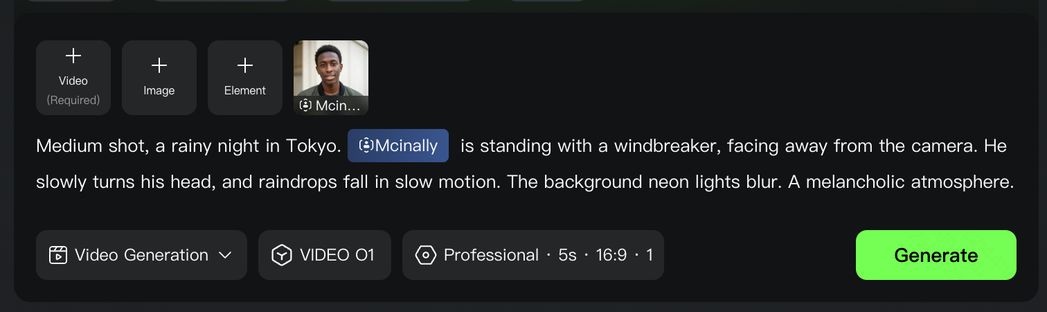
Kling 動画 O1 モデルは、動画生成領域において、参考動画生成、テキストからの動画生成(文生動画)、フレームズからの動画生成、動画内容の追加・削除、動画の指示変換、スタイルのリドロー、カメラワークの拡張といった多様なタスクを、初めて一つの統合モデルの中に融合しました。複数のモデルやツールを切り替える必要はなく、インスピレーションから生成、生成から修正・編集まで、すべての創作プロセスをワンストップで完結できます。
(2)万能指令:マルチモーダル入力で、生成も編集も自由自在
統一モデルの深い意味理解能力により、あなたがアップロードする画像・動画・主体・テキストは、すべて Kling O1 にとって「コマンド」となります。O1 モデルはモダリティの壁を越え、1枚の写真、1本の動画、あるいは1つの主体(1キャラクターの複数アングル)を総合的に理解し、動画のあらゆるディテールを精密に生成します。
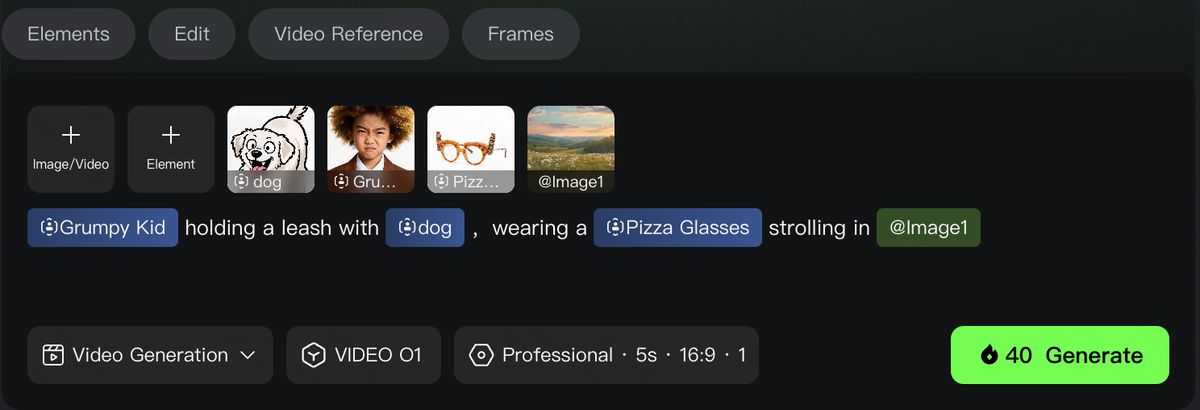
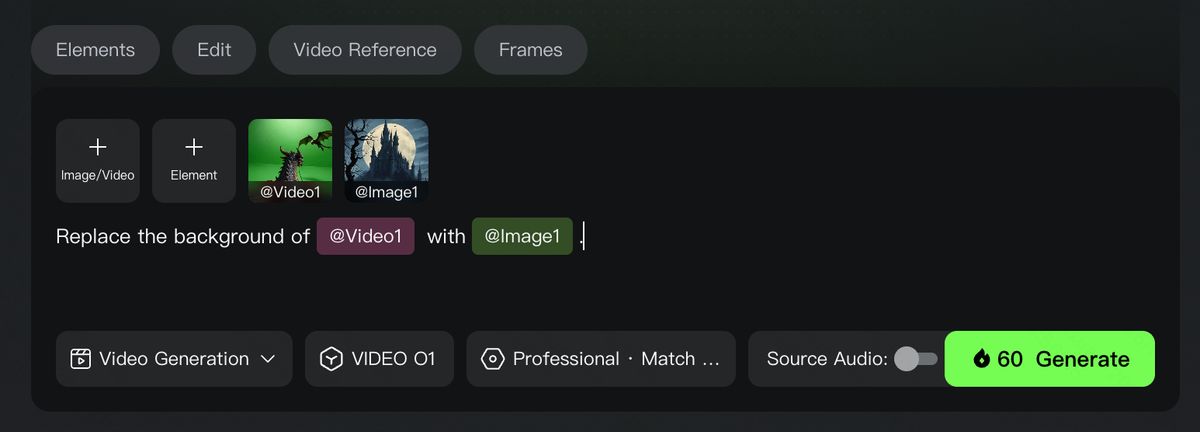
マルチモーダル入力に対応するため、Kling は新しい Kling O1 創作画面 を公開しています:https://app.klingai.com/cn/omni/new
ここから、さまざまな形式の素材を組み合わせて利用できます。
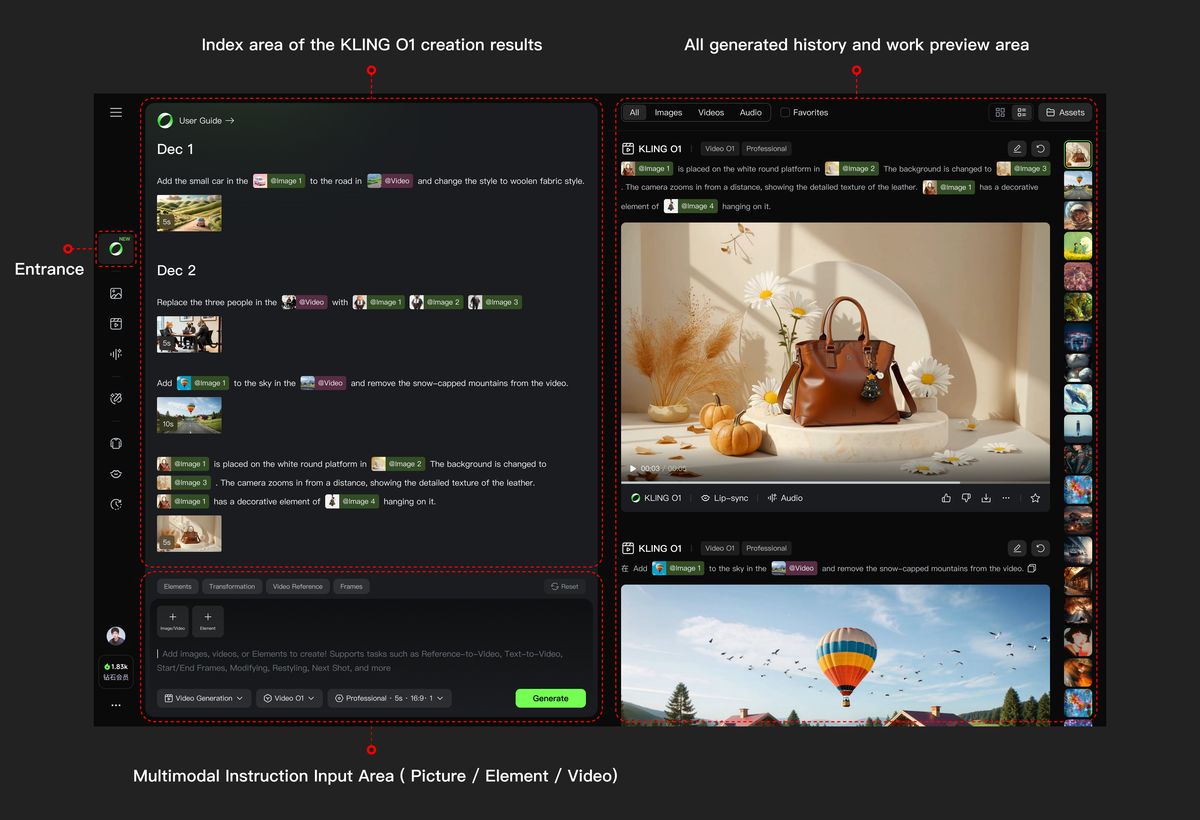
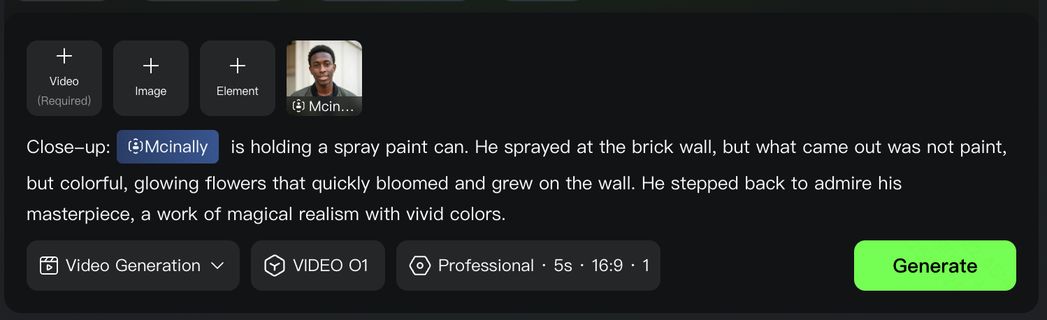
同時に、 Kling O1 によって、煩雑な動画編集・ポストプロダクション作業は、シンプルな対話へと生まれ変わりました。マスクを手動で描く必要も、キーフレームを一つひとつ打つ必要もありません。「通行人を消して」「昼を夕方にして」「主人公の服装を変えて」といったテキストを入力するだけで、モデルが映像のロジックを読み取り、局所的な主体の置き換えから、動画全体のスタイルリドローまで、ピクセルレベルの意味的な再構成を自動で完了します。あなたのテキスト指令こそが、最も効率の良い編集ツールなのです。
上記以外にも、 Kling O1のマルチモーダル指示入力エリアでは、以下のような創作が可能です。
- エレメンツ:画像や主体に含まれるキャラクター/アイテム/背景など、さまざまな要素を参照し、柔軟にクリエイティブな動画を生成できます。
- 指示変換:動画に要素を追加する、要素を削除する、カメラの画角・アングルを切り替えるなど、さまざまな動画編集タスクをこなせます。例えば、動画の主体の変更、背景の差し替え、部分的な変更、動画のスタイル変更、オブジェクトの色変更、天候変更など。
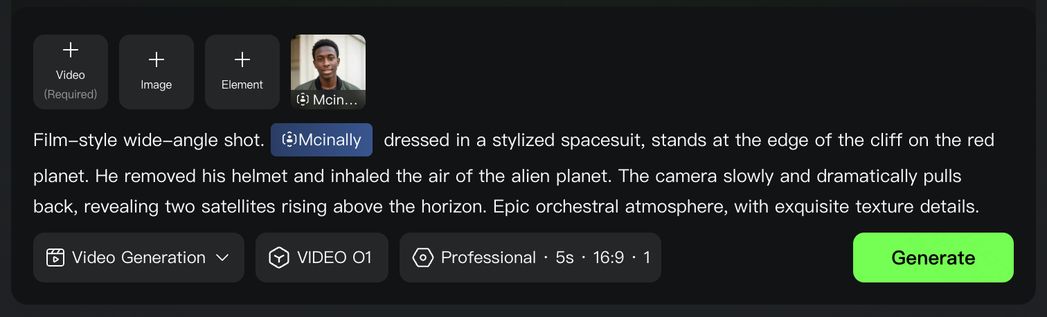
- 参考動画:参考となる動画コンテンツをもとに、前のカット/次のカットを生成したり、動画内のアクションやカメラワークを参考にして、新しい動画をクリエイティブに生成することができます。
- フレームズ やテキストからの動画生成などの機能も、同じモデルで一括してサポートしています。
(3)万能参考:動画の一貫性問題を根本から解決
Kling O1 は、入力された画像や動画の理解能力を大幅に強化し、複数アングルの画像から主体を作成することも可能です。画像や主体の参照を組み合わせることで、Kling O1 は人間の監督のように、あなたの「主役」「小物」「背景」を記憶し、カットがどれだけ切り替わっても、主体の特徴を安定して保ち、すべてのフレームの整合性を維持します。
参考主体
| 「カット1」
| 「カット2」
|

| 
| |
「カット3」
| 「カット4」
| |

| 
|

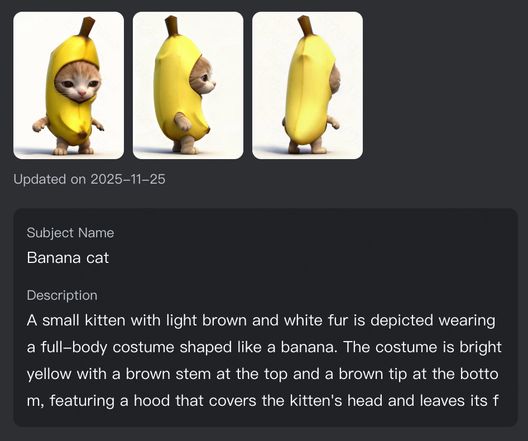
また、単一のキャラクターやアイテムに限らず、Kling 動画 O1 モデルは、強力なマルチ主体の融合能力も備えています。複数の異なる主体同士を自由に組み合わせたり、主体と参考画像をミックスすることも可能です。複雑な群像劇やインタラクションの多いシーンでも、モデルは各キャラクター・各アイテムの特徴を独立して追跡し、保持します。シーンの雰囲気が大きく変化しても、Kling 動画 O1 はすべての「主役」が、異なるカットにおいてもプロレベルで特徴の一貫性を保てるよう保証します。
参考主体 1:バナナ猫
参考主体 2:アジア人少女
| 「カット1」
| 「カット2」
|

| 
|

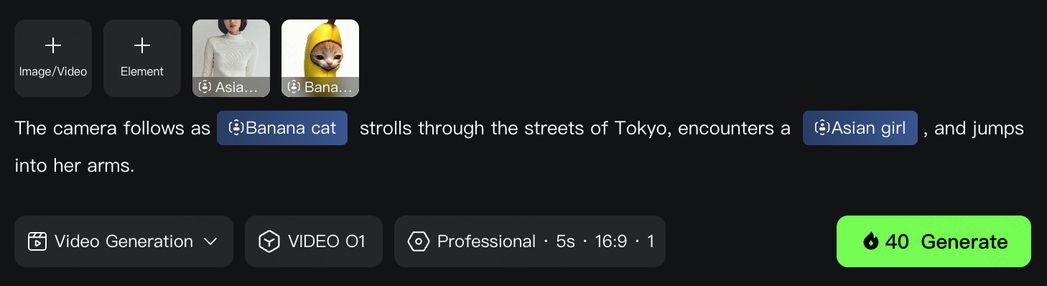
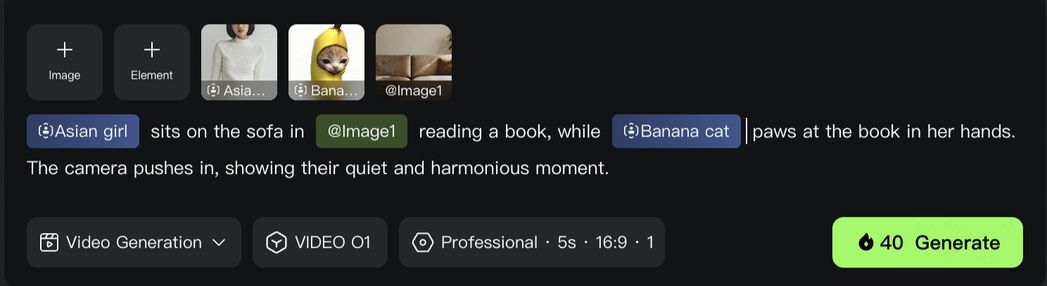
(4)最強コンビネーション:多彩な「化学反応」を生む
Kling O1 モデルは、単一タスクのためだけのツールではありません。「動画に主体を追加しながら背景も変更する」「画像のエレメンツを参照しつつスタイルも変える」など、異なるスキルを組み合わせた生成にも対応しています。一度の生成で多様なクリエイティブパターンを生み出し、無限の創作の可能性を探索できます。

| 
|
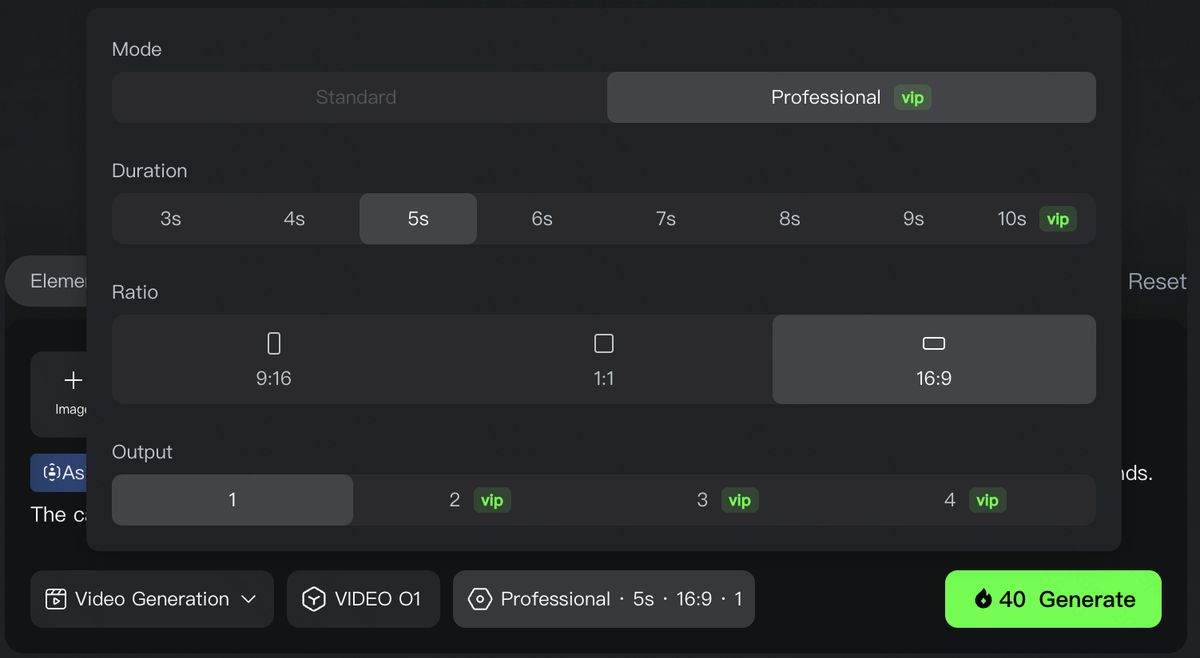
(5)リズムを操る:3〜10秒の自由なストーリーテリング
ひとつひとつの物語、ひとつひとつのカットには、それぞれふさわしい長さと「呼吸」があります。Kling O1 は、3〜10秒の範囲で自由に動画を生成できるため、時間のコントロールをクリエイターに取り戻します。短く鋭いビジュアルインパクトから、じっくりとした物語の構築まで、すべてあなた次第。ストーリーの緩急を自在に操ることができます。
 |
シーン別の活用例
統一マルチモーダルアーキテクチャに基づく根本的なアップデートにより、Kling O1 は「生成」と「編集」を一体化し、発想の制約を取り払います。ゼロからのストーリー構築はもちろん、既存素材の大胆な再構成においても、Kling O1 はシーンのニーズに応じてリファレンスと編集能力を柔軟に呼び出し、映像制作から広告制作まで、多岐にわたるクリエイションを支えます。
映像制作
Kling O1の高い一貫性を持つエレメンツ機能と、主体ライブラリ機能を活用することで、各カットのキャラクターや衣装・小道具を正確に固定し、複数の連続した映像カットを簡単に生成できます。

| 
|
クリエイティブ広告
従来のオフライン広告撮影では、コストが高く、制作期間も長いという課題がありました。Kling O1 では、商品画像+モデル画像+シーン画像をアップロードし、シンプルなテキスト指示を組み合わせるだけで、多数のスタイリッシュな商品紹介動画を素早く生成できます。

| 
|
ファッション・コーディネート
モデルの手配は手間がかかり、背景や服装を変えるたびに撮影を繰り返す必要がある――そんな課題も、Kling O1 で解決できます。あなた専用の「終わらないバーチャルランウェイ」を構築できます。モデル写真と実際の服の写真をアップロードし、テキストで指示を出すだけで、質感やディテールまで忠実に再現した高品質な Lookbook 動画を大量に生成できます。

| 
|
動画ポストプロダクション
複雑なタイムラインやマスク処理はもう忘れてください。Kling O1 なら、動画のポスト修正は、シンプルなテキスト対話で完結します。「背景の通行人を消して」「空を青くして」といった自然言語の編集指示を入力するだけで、モデルが深い意味理解に基づき、ピクセルレベルのインテリジェントな修復と再構成を自動で行います。

| 
|
Kling 動画 O1 モデルの具体的なスキル
エレメンツ
より高いキャラクター/小道具/背景の一貫性を提供するため、Kling O1 は、複数アングルの画像をアップロードして「主体」を作成することをサポートします。
Kling O1のマルチモーダル指示入力エリアでは、1〜7枚の参考画像または主体をアップロードし、人物・キャラクター・小物・衣装・背景などの要素を自由に組み合わせられます。そしてテキストでそれぞれのディテールや相互のインタラクションを記述することで、静止した要素を動画の中で躍動させることができます。
テキスト指令 = 「複数主体の詳細描写」+「主体間のインタラクション/動作」+「環境背景」+「カメラワーク/光影/スタイル等の視覚的要素」
 |  |
 |  |
 |  |
指示変換
Kling O1 では、テキスト/画像/主体といったマルチモーダルな入力を自由に組み合わせて O1 モデルを駆動し、元の動画に対して主体や背景の追加・変更・削除を行えます。さらに、動画のスタイル、天候、色合い、質感、画角・アングルなども柔軟に変更することが可能です。
動画コンテンツ追加
| 文型例:「@動画」に「@画像」のコンテンツを追加 | 文型例:「@動画」に「追加コンテンツの記述」を追加 |
 | 
|
| 文型例:「@動画」に「@主体」を追加 | 文型例:「@動画」に「@画像」と「@主体」を追加 |

| 
|
動画コンテンツ削除
文型例:「@動画」から「削除対象の記述」を削除

|
|
視点/画角の切り替え
文型例:「@動画」の「他の視点/画角、例えば、正面クローズアップ/ロングショット]」を生成

| 
|
動画コンテンツ修正
動画の主体変更
| 文型例:「@動画」中の「指定主体の記述」を「テキスト記述」に変更 | 文型例:「@動画」中の「指定主体の記述」を「@画像」に変更 |
| 
|
| 文型例:「@動画」中の「指定主体の記述」を「@主体」に変更 | |

| 
|
動画の背景変更
| 文型例:「@動画」の背景を「背景内容の記述」に変更 | 文型例:「@動画」の背景を「@画像」の「背景の記述」に変更 |

| 
|
動画の一部変更
| 文型例:「@動画」中の「変更対象の部位を記述」を「変更後の内容を記述」に変更 | 文型例:「@動画」中の「変更対象の部位を記述」を「@画像1」の「対象内容を記述」に変更 |

| 
|
動画のスタイル変更
文型例:「@動画」を「スタイル名(例:アメリカンカートゥーン/日本のアニメ/サイバーパンク/ピクセルアート/水墨画/水彩画/フィギュア風…)」に変更
| アメリカンカートゥーン | 日本のアニメ |

| 
|
| サイバーパンク | ピクセルアート |
 | |
| 水墨画 | 水彩画 |

| 
|
| 粘土アニメ | フェルトアート |

| 
|
| フィギュア風 | モネ風 |

| 
|
文型例:「@動画」を「@画像」のスタイルに変更

|
物の色変更
| 文型例:「@動画」中の「変更対象の記述」を「色名称」に変更 | 文型例:「@動画」中の「変更対象の記述」の色を「@画像」の色に変更 |

| 
|
動画の天候変更
文型例:「@動画」の天候を「目標天候」に変更

| 
|

| 
|
動画クロマキー処理
| 文型例:「@動画」の背景をグリーンバックに変更し、[保持する内容を記述]を保持 |

|
動画エフェクトの演出
テキスト指示だけで、動画内の要素に炎のエフェクトを追加したり、環境全体を凍らせたりすることができます。また、人物の顔に模様を追加したり、赤目のエフェクトを付けたりも可能です。さらに、動画内の主体に対して、画像をもとにした再描画を行い、元の主体と差し替えることで、よりインパクトのあるビジュアル表現を実現できます。

| 
|

| 
|
参考動画
3〜10秒の動画を参考素材としてアップロードし、テキスト・画像・主体などの指示と組み合わせることで、次のカットを生成したり、動画内のアクション/カメラワークを参照して、新たな動画シーンを生成することができます。
次のカットを生成
文型例:「@動画」を基にに次のカットを生成:「カット内容を記述」

| 「@動画」を基に次のカットを生成:後部座席からミディアムショットで前席の中高年男性と若い男性を撮影。二人は微かに背を向け合い、対立の三角構図を形成。それぞれが車窓へ視線を向ける。背景はボケ処理。緊迫感と抑圧感を持ちながらも抑制された雰囲気で、密閉空間での感情の対峙を表現。ソフトな自然光が車内に差し込み、仄暗いオリーブグリーンとブラウンのトーンに、微細なフィルムグレインを加えた映像。 |
前のカットを生成
文型例:「@動画」を基に前のカットを生成:「カット内容を記述」

| 「@動画」を基に前のカットを生成:カメラが右に移動し、黒いスーツを着た中高年男性を追い、画面右側の運転席ドアへ向かう。男性は左手でドアを開け、運転席に座り、車体がわずかに揺れる。その後、画面左前景の若い男性が話し始め、中高年男性を見つめる。 |
カメラワークを参考
文型例:「@画像1」をスタートフレームに設定し、「@動画」のカメラワークを適用

|
|
動画の動きを参考
文型例:「@動画」内の「キャラクター」の動きを参考に、「@画像」に写る「キャラクター」を動かす
 | |
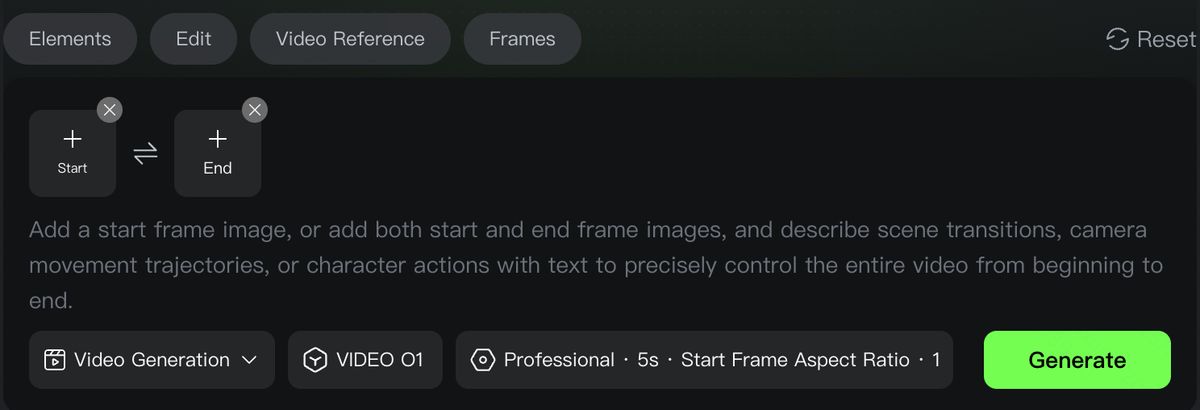
フレームズ
デフォルトモードでは、以下のような文型で、どの画像が先頭フレームで、どの画像が最後のフレームかをテキストで指定できます。さらに、シーンの変化やカメラの動き、キャラクターのアクションを記述することで、動画の「始まりから終わりまで」を精密にコントロールできます。
文型例:「@画像1」をスタートフレームに固定し、「以降の画面変化を記述」
文型例:「@画像1」をスタートフレームに固定、「@画像2」をエンドフレームに固定し、「開始フレームから終了フレームまでの画面変化を詳細に記述」。
また、スキルエリアの「フレームズ」アイコンをクリックすると、先頭フレームと最後のフレーム用の画像アップロード枠を呼び出せるため、より視覚的に操作できます。(現時点では、最後のフレームのみを指定した生成には対応していません)

| 
|
テキストからの動画生成
入力エリアにテキストのみを入力し、素材をアップロードせずに生成を実行すると、「テキストからの動画生成」となります。この場合、プロンプトの情報量や細かさが、生成される動画クオリティを大きく左右します。
文型例: 主体(主体の説明)+ 動き + シーン(シーンの説明)+(カメラワーク+光と影+雰囲気 など)

| 
|
さらに多様な組み合わせ
上記の各スキルに加えて、さまざまな素材を組み合わせることで、想像力を最大限に発揮し、さらに多くのサプライズある結果を得ることができます。例えば、「エレメンツ + スタイル変更」、「主体を削除 + 主体を追加」、「背景変更 + 主体追加 + スタイル変更」、「主体追加 + スタイル変更」 など。
|
|
| 
|

|
|
FAQ
入力可能な素材の条件は?
- 画像:最大7枚までアップロード可能。縦横いずれかのサイズが 300px 以上、ファイルサイズ 10MB 以下、形式は .jpg / .jpeg / .png に対応。
- 動画:1本までアップロード可能。長さ 3〜10秒、ファイルサイズ 200MB 以下、解像度 2K 以下。
- 主体:複数アングルの画像(最大4枚)をアップロードまたは AI 生成したものを組み合わせて、1つの主体として使用できます。これにより、モデルにより豊富な参照情報を与えることができます。
補足:入力エリアに動画がある場合、画像+主体は合計4つまでアップロード可能です。動画が存在しない場合、画像+主体は合計7つまでアップロード可能です。
Kling 動画 O1 の価格は?
Kling 動画 O1 は、現在「高品質モード」のみ対応しています。生成コストは、入力状況と生成する動画の長さによって変動します。動画を入力するかどうかによっても、価格が異なります。
- 動画入力なしの場合:1秒あたり 8 クレジット。例えば、5秒 = 40 クレジット、10秒 = 80 クレジット。
- 動画入力ありの場合:1秒あたり 12 クレジット。例えば、5秒 = 60 クレジット、10秒 = 120 クレジット。







