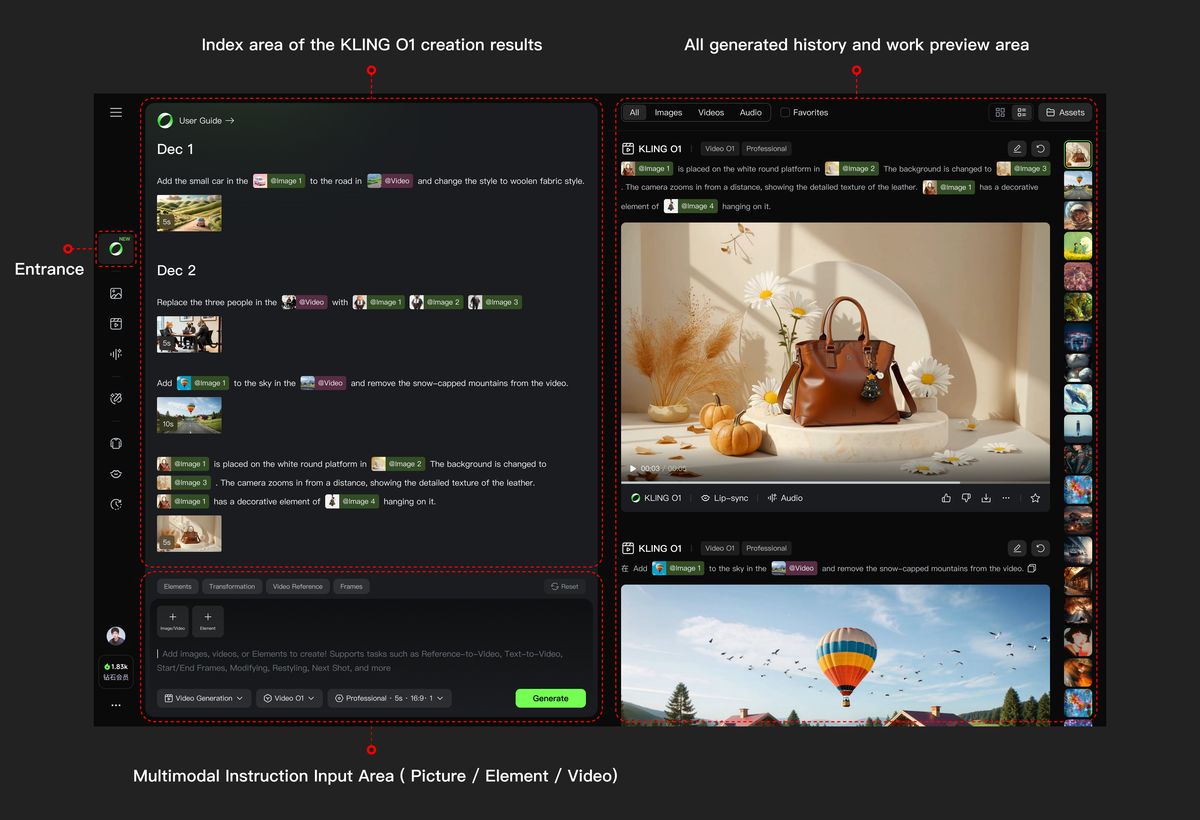
Kling O1은 Multi-modal visual language (MVL) 이념을 적용하여, 자연어를 의미적 기반으로 삼고 비디오, 이미지, 피사체 등 멀티모달 정보를 결합하여 사용자의 의도를 정확하게 이해함으로써 조작은 더 직관적으로, 창작은 더 효율적으로 만듭니다.
비디오 O1 모델의 5가지 핵심 하이라이트
(1) 새로운 엔진: 세계 최초의 통합 멀티모달 비디오 모델
KlingAI 비디오 O1 모델은 비디오 생성 영역 최초로 레퍼렌스 생성 비디오, 텍스트 생성 비디오, 스타트 엔드 프레임 생성 비디오, 비디오 내용 추가/삭제, 비디오 수정 변환, 스타일 리렌더링, 화면 확장 등 다양한 작업을 하나의 통합 모델에 융합합니다. 여러 모델과 도구를 번갈아 가며 사용할 필요 없이, 영감에서 생성으로, 생성에서 수정으로 이어지는 모든 창작 과정을 원스톱으로 완료할 수 있습니다.
(2)전능한 명령: 멀티모달 입력, 만능 창작 편집
통합 모델의 심층적인 언어 이해력에 기반하여, 사용자가 업로드한 이미지, 비디오, 주체, 텍스트는 KlingAI O1 보기에는 모두 '지시'가 됩니다. O1 모델은 모달의 한계를 깨고 업로드한 한 장의 사진, 하나의 비디오 또는 주체(캐릭터의 다양한 시점)를 종합적으로 이해하여 비디오의 각종 디테일을 정교하게 생성할 수 있습니다.
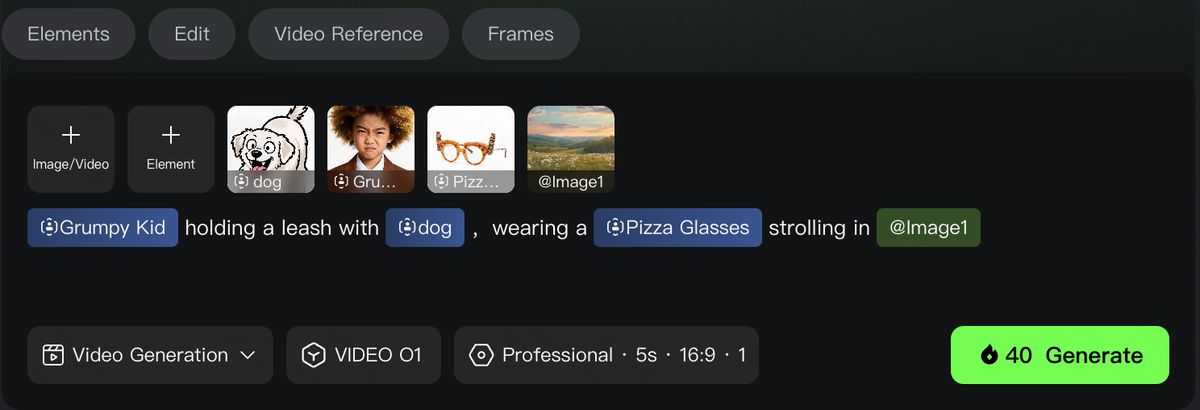
멀티모달 입력에 맞춰 Kling은 새로운 Kling O1 창작 인터페이스 https://app.klingai.com/cn/omni/new 를 출시하여 다양한 형식의 소재를 종합적으로 편리하게 사용할 수 있도록 합니다.
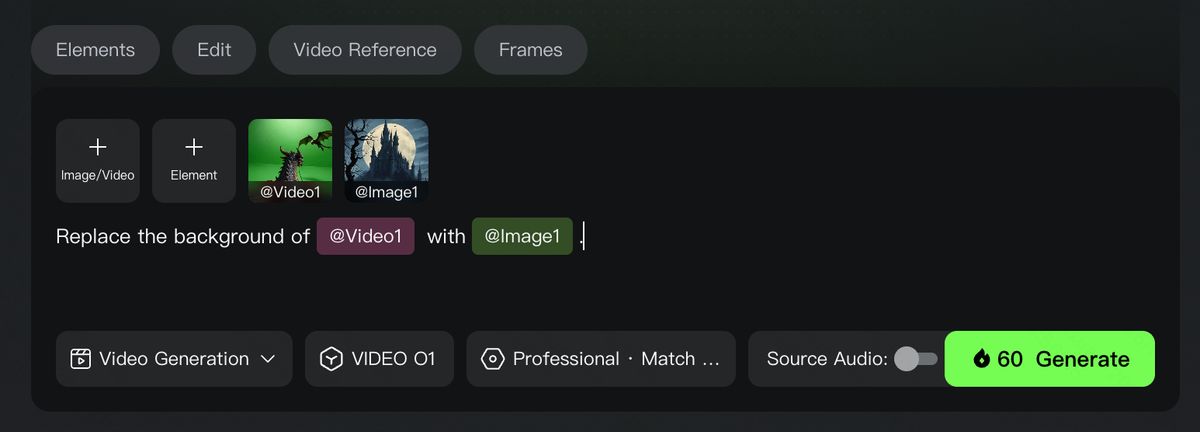
동시에 KlingAI O1은 번거로운 후반 편집 작업을 간단한 대화로 바꿔줍니다. 수동으로 마스킹하거나 키프레임을 잡을 필요 없이 "행인 제거", "낮을 황혼으로 변경" 또는 "주인공 의상 교체"라고 입력하기만 하면 모델이 영상의 논리를 이해하여 부분적인 피사체 교체부터 전체적인 비디오 스타일 리렌더링까지 픽셀 수준의 의미 재구성을 자동으로 완료합니다. 당신의 텍스트 지시는 가장 효율적인 수정 툴입니다.
위의 예시 외에도 KlingAI O1 멀티모달 지시 입력창에서 다음과 같은 창작을 수행할 수 있습니다.
- 이미지/피사체 참고: 이미지/피사체 속의 캐릭터/소품/장면 등 다양한 엘리먼트 참고하기를 지원하여 창의적인 비디오를 마음대로 생성할 수 있습니다.
- 지시 변환: 비디오 내용 추가, 비디오 내용 삭제, 샷 사이즈 및 앵글 전환. 또한 비디오 주체 수정, 비디오 배경 수정, 비디오 부분 수정, 비디오 스타일 수정, 물체 색상 수정, 비디오 날씨 수정 등 다양한 비디오 수정 작업을 수행할 수 있습니다.
- 비디오 참고: 비디오 내용을 참고하여 이전 장면/다음 장면을 생성하거나, 비디오 동작/카메라 무빙을 참고하여 창의적인 생성을 진행할 수 있습니다.
- 스타트 엔드 프레임, 텍스트 생성 비디오 등의 능력도 함께 지원합니다.
(3) 전능한 참고:비디오 일관성 난제 완벽 해결
KlingAI O1 근본적으로 입력 이미지 및 비디오에 대한 이해를 강화했으며, 다각도 이미지를 통한 주체 생성을 지원합니다. 이미지/주체 참고를 통해 KlingAI O1은 인간 감독처럼 주인공/소품/장면 등을 기억하여 카메라가 어떻게 무빙하든 주체의 특징을 항상 한결같이 유지하여 모든 프레임의 화면이 정교하게 이어지도록 보장합니다.
참고 주체
| [장면 1]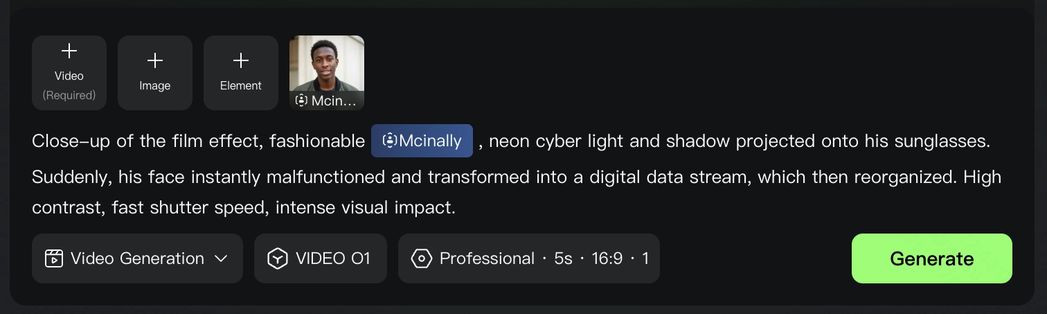 | [장면 2]
|

| 
| |
[장면 3]
| [장면 4]
| |

| 
|

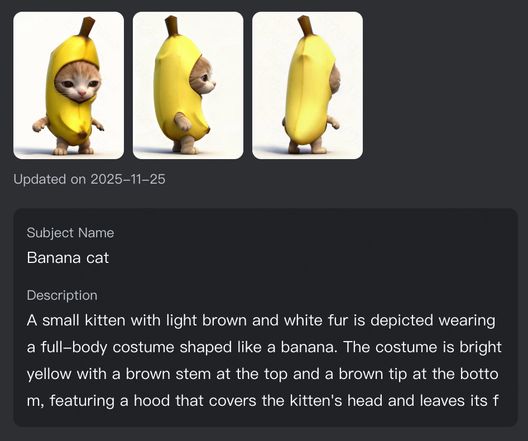
또한 단일 캐릭터/물품에 그치지 않고, KlingAI 비디오 O1 모델은 강력한 다중 피사체 융합 능력을 갖추고 있습니다. 여러개의 서로 다른 피사체를 자유롭게 조합하거나 주체와 레퍼렌스 이미지를 믹스 매치할 수 있습니다. 복잡한 군상극이나 인터랙티브 장면에서도 모델은 각각의 캐릭터나 소품의 특징을 독립적으로 인식하여 고정(Lock-in)하고 유지할 수 있습니다. 장면의 분위기가 어떻게 급변하든, 비디오 O1은 당신의 모든 '주인공'이 서로 다른 장면에서도 업계 최고 수준의 일관성을 구현하도록 보장합니다.
참고 주체 1:바나나 고양이
참고 주체 2:한국 소녀
| [장면1]
| [장면2]
|

| 
|

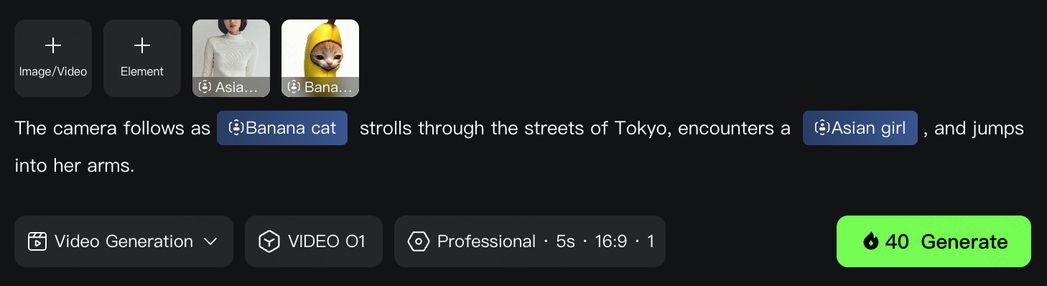
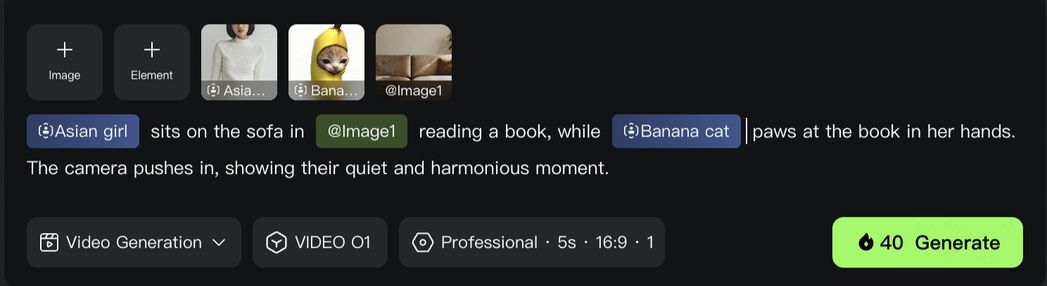
(4)초강력 조합:더 많은 창의적 화학 반응
KlingAI O1 모델은 단일 작업에 그치지 않고 서로 다른 기능의 조합을 지원합니다. 예를 들어 "비디오에 주체를 추가하는 동시에 배경 수정", "이미지 참고 생성 시 스타일 수정" 등 한 번의 생성으로 다양한 창의적 변화를 실현해, 무한한 창작 가능성을 탐구할 수 있습니다.

| 
|
(5)리듬 컨트롤: 3~10초 자유 서사 생성 지원
모든 이야기, 모든 장면에는 그에 알맞은 길이와 호흡이 있습니다. KlingAI O1은 3~10초 자유 생성을 지원하여 시간 정의의 자유를 당신에게 돌려드립니다. 짧고 강렬한 시각적 임팩트든, 길게 이어지는 스토리 전개든 당신이 자유롭게 완벽한 컨트롤을 하여 서사의 완급을 조절할 수 있습니다.
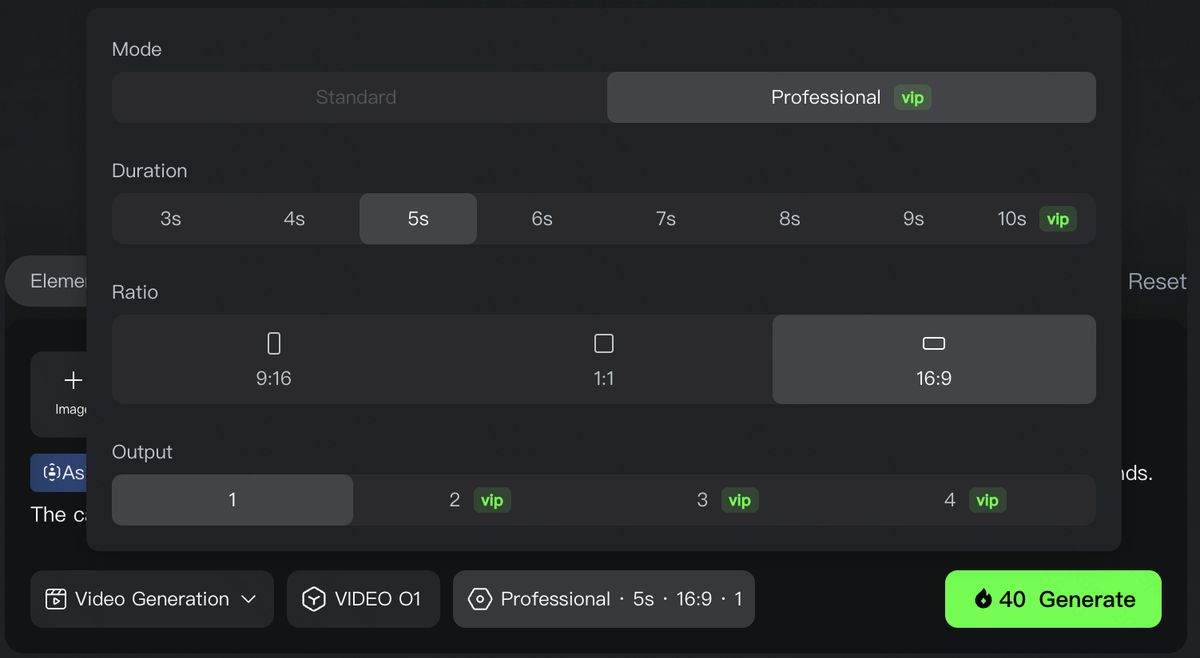
장면 활용
통합 멀티모달 아키텍처의 근본적인 혁신을 통해 KlingAI O1은 생성과 편집을 하나로 통합하여 더 이상 아이디어가 제한받지 않게 합니다. 제로에서 시작하는 서사 생성, 혹은 기존 소재에 대한 심층 재구성이든, KlingAI O1은 다양한 장면의 요구에 따라 참고 및 편집 능력을 유연하게 발휘하여 영화부터 광고까지 다양한 창작을 완성할 수 있습니다.
영화/영상 창작
KlingAI O1의 강력한 일관성을 가진 이미지/피사체 참고를 활용하고 주체 라이브러리 기능과 결합하면, 각 스토리보드의 캐릭터 및 의상/소품을 정확하게 고정하여 연결성이 있는 여러 영상 샷을 손쉽게 창작 및 생성할 수 있습니다.

| 
|
창의적 광고
기존의 실사 광고 촬영은 비용이 높고 제작 주기가 깁니다. KlingAI O1에서는 상품 이미지 + 모델 이미지 + 장면 이미지를 업로드하고 간단한 지시 설명을 곁들이기만 하면, 감각적인 제품 광고 영상 여러 개를 빠르게 생성할 수 있습니다.

| 
|
패션 룩북(Lookbook)
모델 촬영 예약의 번거로움, 배경/의상 교체에 따른 반복 촬영이 필요 없습니다. KlingAI O1을 사용하여 끝나지 않는 당신만의 가상 런웨이를 구축하세요. 모델 + 의상 실사 이미지를 업로드하고 프롬프트를 입력하면, 의상의 질감과 디테일을 완벽하게 재현하여 고품질 Lookbook 비디오를 대량 생산할 수 있습니다.

| 
|
비디오 후반 작업
복잡한 트해킹과 마스킹은 잊으세요. KlingAI O1에서 비디오 후반 수정은 간단한 대화 한 마디면 됩니다. 자연어 편집을 활용하여 "배경의 행인 삭제", "하늘을 파랗게 변경" 등을 입력하면 모델이 심층 의미 이해를 통해 픽셀 수준의 스마트 복원 및 재구성을 자동으로 완료합니다.

| 
|
비디오 O1 모델 구체적 스킬
이미지/피사체 참고
더 나은 캐릭터/소품/장면 일관성을 제공하기 위해 KlingAI O1은 최초로 다각도 이미지 업로드를 통한 '주체' 생성을 지원합니다.
KlingAI O1의 멀티모달 프롬프트 입력창에서 1~7장의 레퍼렌스 이미지나 피사체를 업로드하여 인물, 캐릭터, 소품, 의상, 장면 등의 엘리먼트를 자유롭게 조합하고, 텍스트로 그들 간의 멋진 상호작용을 정의하여 정적인 요소들이 비디오 속에서 살아 움직이게 할 수 있습니다.
텍스트 프롬프트 = [여러 피사체 디테일 묘사] + [피사체 간 상호작용/동작] + [환경 배경] + [카메라 무빙/조명/스타일 등 시청각 언어]

| 
|

| 
|

|
|
지시 변환
KlingAI O1에서는 멀티모달(텍스트/이미지/피사체 등) 입력 언어를 마음대로 조합하여 O1 모델을 구동할 수 있습니다. 원본 비디오에 대해 피사체와 배경의 추가, 수정, 삭제를 손쉽게 할 수 있으며, 비디오의 스타일, 날씨, 색상, 재질, 샷 사이즈 및 앵글 등도 수정할 수 있습니다.
비디오 내용 추가
| 형식:【@비디오】에 【@이미지】 속 콘텐츠를 추가해 줘 | 형식:【@비디오】에 [추가할 콘텐츠 묘사]을/를 추가해 줘 |

|
|
| 형식:【@비디오】에 【@피사체】을/를 추가해 줘 | 형식: 【@비디오】에 【@이미지】와 【@주체】를 추가해 줘 |
| |
비디오 내용 삭제
형식:【@비디오】에 [삭제할 콘텐츠 묘사]을/를 삭제해 줘
| |
앵글 / 샷 사이즈 전환
형식:【@비디오】의 [다른 시각/샷 사이즈, 예: 정면 클로즈업/롱 샷]을/를 생성해 줘
| |
비디오 내용 수정
비디오 피사체 수정
| 형식:【@비디오】속 [지정 피사체 묘사]을/를 [텍스트 설명](으)로 수정해 줘 | 형식:【@비디오】속 [지정 피사체 묘사]을/를 【@이미지】로 수정해 줘 |
| |
| 형식:【@비디오】속 [지정 피사체 묘사]을/를 【@주체】(으)로 수정해 줘 | |
| |
비디오 배경 수정
| 형식:【@비디오】 속 배경을 [배경 내용 묘사](으)로 수정해 줘 | 형식:【@비디오】 속 배경을 【@이미지】 속 [배경 묘사](으)로 수정해 줘 |
| |
비디오 부분 수정
| 형식:【@비디오】 속 [피사체 국소 부위 묘사]을/를 [목표 내용 묘사](으)로 수정해 줘 | 형식: 【@비디오】 속 [주체 국소 부위 묘사]을/를 【@이미지1】 속 [목표 내용 묘사](으)로 수정해 줘 |
| |
비디오 스타일 수정
형식:【@비디오】를 [스타일형 어휘, 예시: 미국식 카툰/일본식 애니메이션/사이버펑크/픽셀 스타일/수묵(水墨) 스타일/수채(水彩) 스타일/피규어 스타일...](으)로 수정해 줘
| 미국식 카툰 | 일본식 애니메이션 |
| |
| 사이버펑크 | 픽셀 스타일 |
| |
| 수묵(水墨) 스타일 | 수채(水彩) 스타일 |
| |
| 클레이 스타일 | 양모펠트 스타일 |
|
|
| 피규어 스타일 | 모네 스타일 |
| |
형식: 【@비디오】를 【@이미지1】의 스타일로 수정해 줘
|
물체 색상 수정
| 형식:【@비디오】 속 [수정 대상 묘사]를 [색상 어휘]로 바꿔 줘 | 형식:【@비디오】 속 [수정 대상 묘사]을/를 【@이미지】 속 색상으로 바꿔 줘 |
| |
비디오 날씨 수정
- 형식: 【@비디오】의 날씨를 [목표 날씨](으)로 수정해 줘
| |
| |
비디오 크로마키 작업
| 형식:【@비디오】의 배경을 그린 스크린으로 바꾸고 [보존할 내용 묘사]은/는 남겨 줘 |
|
비디오 특수 효과 연출
텍스트를 사용하여 비디오 속 엘리먼트에 불꽃을 추가하거나, 비디오 속 환경을 얼어붙게 만들 수 있습니다. 또한 비디오 속 인물에게 얼굴 문양을 추가하거나 레드아이 효과를 넣을 수도 있습니다. 비디오 속 피사체를 이미지로 리렌더링한 후, 비디오 원본 주체와 교체하여 더 매력적인 시각 효과를 얻을 수도 있습니다.
| |
| |
영상 참고
3~10초의 비디오를 참고용으로 업로드하고 텍스트, 이미지 또는 피사체 등의 프롬프트를 결합하여 다음 장면을 생성할 수 있습니다. 혹은 비디오 내 동작/카메라 무빙을 참고하여 영상을 생성할 수도 있습니다.
다음 장면 생성
형식: 【@비디오】에 기반하여 다음 장면 생성: [샷 내용 묘사]
| 【@비디오】에 기반하여 다음 장면 생성: 카메라는 뒷좌석에 위치하며, 앞줄의 중장년 남성과 젊은 남성을 미디엄 샷으로 촬영. 두 사람은 등을 살짝 돌리고 있어 대립적인 삼각형 구조를 형성함. 각자 차창 밖으로 고개를 돌려 밖을 보고 있음. 배경은 흐릿하게 처리. 긴장되고 억압적이지만 절제된 분위기로 밀폐된 공간 속의 감정적 대립 같음. 부드러운 자연광이 차 안으로 들어와 어두운 올리브색과 갈색 톤을 조성하며, 미세한 필름 그레인 질감을 동반함. |
이전 장면 생성
형식: 【@비디오】에 기반하여 이전 장면 생성: [샷 내용 묘사]
| 【@비디오】에 기반하여 이전 장면 생성: 카메라가 오른쪽으로 이동하며 검은 정장을 입은 중노년 남성을 팔로우 샷으로 촬영, 화면 우측의 운전석 문 쪽으로 걸어감. 그 후 중노년 남성이 왼손으로 차 문을 열고 운전석에 앉으면 차가 살짝 흔들림. 화면 좌측 전경의 젊은 남성은 말을 하면서 중노년 남성을 쳐다봄. |
비디오의 카메라 무빙 참고
형식: 【@이미지1】을 스타트 이미지로 삼고, 【@비디오】의 카메라 무빙을 【@이미지1】에 적용해 줘
| |
비디오 동작 참고
형식:【@비디오】 속 [캐릭터]의 동작을 참고하여, 【@이미지】 속 [캐릭터]이/가 움직이게 해 줘
| |
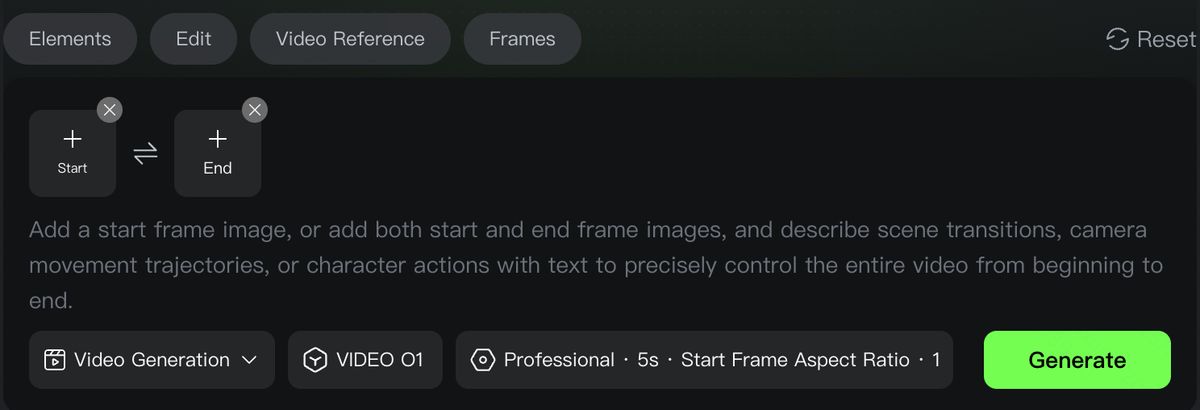
스타트 엔드 프레임
기본 모드에서 아래 구문을 참고하여 어떤 이미지가 스타트 이미지이고 어떤 이미지가 엔드 이미지인지 텍스트로 직접 설명할 수 있습니다. 장면 전환, 카메라 무빙 궤적 또는 캐릭터 동작을 묘사하여 비디오의 시작부터 끝까지의 전 과정을 정밀하게 제어할 수 있습니다.
형식:【@이미지1】을 스타트 이미지로 사용/고정하고, [이후 화면의 변화 묘사];
형식:【@이미지1】을 스타트 이미지로 사용/고정하고, 【@이미지2】를 엔드 이미지로 사용/고정하여, [스타트 프레임과 엔드 프레임 사이의 변화 내용 묘사].
스킬 존의 '스타트 엔드 프레임' 아이콘을 클릭하여 이미지 업로드 슬롯을 불러오면 더 직관적으로 조작할 수 있습니다. (현재 '엔드 이미지'만 단독 생성하는 것은 지원하지 않음)
| |
텍스트 생성 비디오
입력창에 텍스트를 입력하고 소재를 업로드하지 않은 채 생성 버튼을 누르면, 텍스트 생성 비디오 창작이 됩니다. 텍스트 생성 비디오에서 프롬프트가 구체적이고 풍부할수록 생성된 비디오의 효과를 결정합니다.
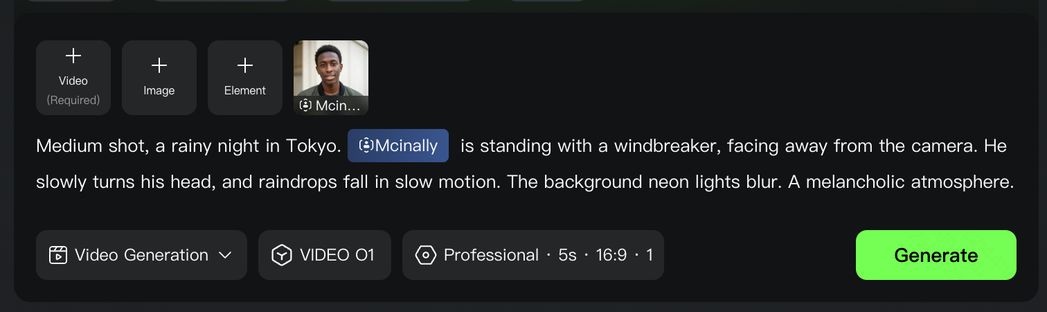
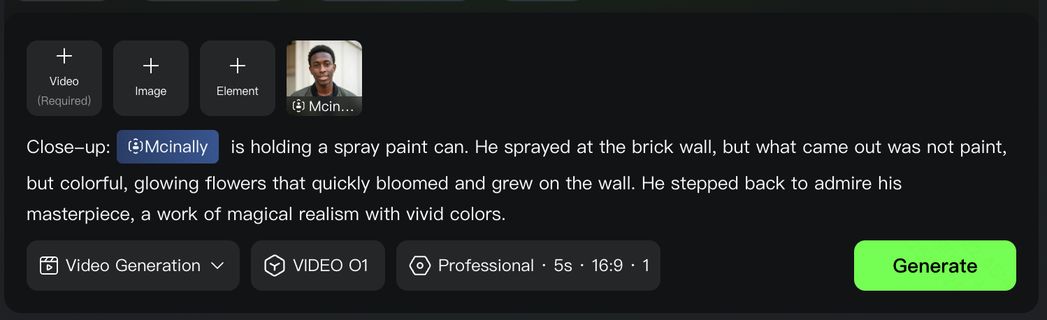
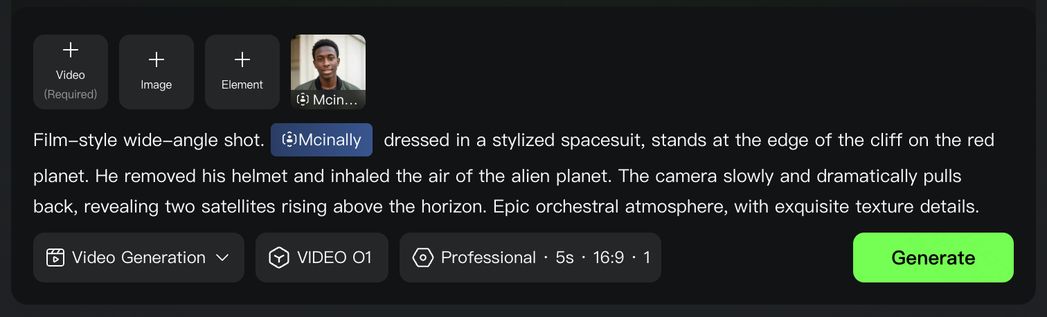
형식: 주체(주체 묘사) + 운동(움직임) + 장면(장면 묘사) + (렌즈 언어 + 조명 + 분위기)
|
더 많은 조합 및 시도
위 기능 외에도 각종 소재를 조합하고 상상력을 충분히 발휘하여 더 놀라운 결과를 얻을 수 있습니다. 예를 들어 '이미지/주체 참고 + 스타일 수정', '주체 삭제 + 신규 주체 추가', '배경 수정 + 주체 추가 + 스타일 수정', '주체 추가 + 스타일 수정' 등입니다.
| |
| |
| |
FAQ
입력 지원 소재
- 이미지: 최대 7장까지 업로드 가능. 이미지 가로세로 사이즈 300px 이상, 파일 크기 ≤ 10MB, 형식은 .jpg / .jpeg / .png
- 비디오: 3초 ≤ 길이 ≤ 10초, 파일 크기 ≤ 200MB, 해상도 ≤ 2k의 비디오 하나를 업로드 가능
- 주체: AI로 생성한 여러 다른 시점의 이미지(최대 4장)를 업로드/사용하여 하나의 '주체'로 조합 가능. 모델에 더 풍부한 참고 정보를 제공함.
- 비고: 입력창에 비디오가 있을 경우, 이미지/주체는 최대 총 4개까지 업로드 가능; 비디오가 없을 경우, 이미지/주체는 최대 총 7개까지 업로드 가능.
비디오 O1 가격
비디오 O1은 현재 고품질 모드만 지원합니다. 생성 가격은 입력 소스과 생성 비디오의 길이에 따라 달라집니다. 비디오 입력 유무가 생성 가격에 영향을 미칩니다.
- 비디오 입력 없음: 8 크레딧/초. (5초는 40 크레딧, 10초는 80 크레딧)
- 비디오 입력 있음: 12 크레딧/초. (5초는 60 크레딧, 10초는 120 크레딧)







